The hardest bugs are those where your mental model of the situation is just wrong, so you can’t see the problem at all.
—— Brian Kernighan
摘要
内存模型是程序员理解并发程序,尤其是无锁并发程序的必备工具。这篇文章是我试图讲解这一知识的尝试,也兼做我对这一知识调查的总结。本文分为两个部分,第一部分介绍并发编程中的基本问题——原子性(Atomicity)问题和访存顺序(Memory Ordering)问题以及造成它们的源头:CPU和编译器。第二部分讲解编程语言提供的,让程序员对付这两个问题的工具——内存模型。第二部分将会通过介绍三个从抽象到具体的模型:SC-DRF,acquire-release和happens-before来引入和讲解内存模型的高层心智模型。本文的目标读者是使用过或至少知道并发编程基础工具(线程,锁,信号,并发队列等)并希望理解内存模型的程序员。
引子:一记破梦闷棍
计算机系统里到处都是抽象。而抽象,其实就是方便行事的谎言。只要建立起抽象,使用方就能专心完成自己的任务,而不需要操心实现方是怎么做的;实现方也可以进行各种各样的优化,让使用方什么都不用做,不需要知道下面到底发生了什么,只需要升级一下,就能得到更好的性能。
高级语言就是一种抽象。
一直以来,编译器和CPU的设计者们都在试图维护这样的谎言:
电脑只会按程序员写的做,一条一条的从上往下执行程序
一切都很好。程序员们可以用这个简单的心智模型快速地用代码实现功能。编译器和CPU的设计者们只要不破坏这个谎言,就能随心所欲地进行优化。程序员只要把写好的程序扔给编译器,把编译器吐出来的可执行文件扔给操作系统,操作系统安排CPU执行这段程序,就能让电脑按程序员的命令干活。
直到有一天,抢占式调度和多核处理器出现了。
为了充分利用多核处理器的能力,程序员们开始编写多线程代码。程序员们带着上面的抽象,是这么思考的:
电脑里有多个线程同时运行,每个线程一条一条地从上往下执行自己的程序,线程之间以语句为粒度交错执行(interleaved execution),并发地操作内存。
举个例子:
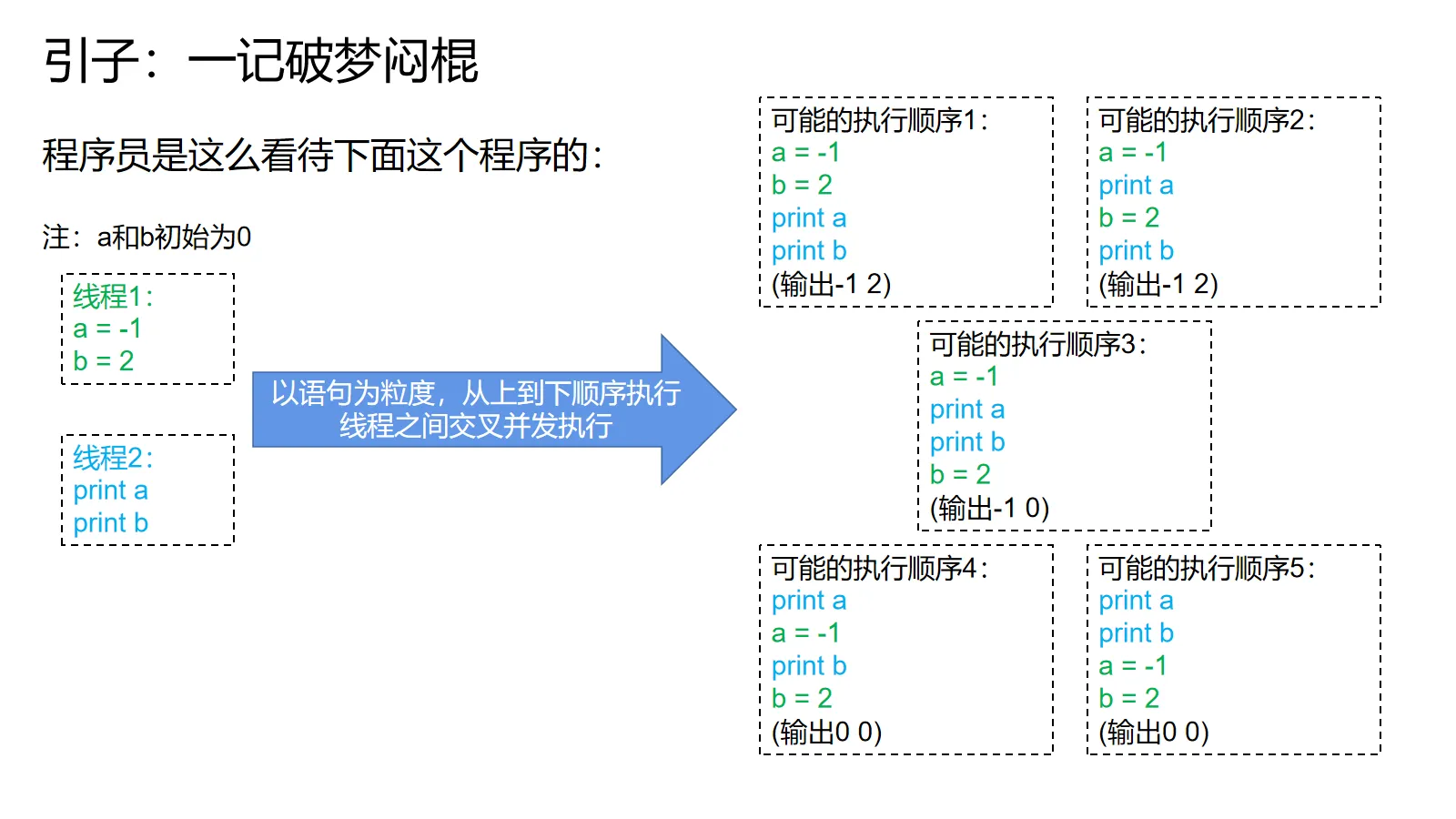
一个线程先a=-1,然后b=2,另一个线程先读a再读b。线程内顺序执行,线程间交错执行。在保持线程内程序顺序的前提下,把语句排列组合就有上面的执行顺序。
按道理来说,线程2的读操作只会产生三种结果:要么看到a=0,b=0(读都发生在写之前),要么看到a=-1,b=0(读a发生在写a后面,读b发生在写b前面),要么看到a=-1,b=2(读都发生在写之后)。不可能发生看到a=0,b=2的现象,因为线程1里写a的语句是在写b前面的,后面的不可能先发生。

但是,一旦程序员把这个程序变成代码跑起来,就会发现各种诡异的现象: 有的时候,另一个线程会输出b=2,但是a=0 有的时候,另一个线程print出a的值不是-1,而是一个非常大的正数
而这只是各种神奇现象的冰山一角: 有的程序员让两个线程同时各++一个共享变量1000次,等它们结束后再打印值,却发现输出了一个1。 有的程序员让一个线程把一个int64_t变量赋值为-1,同时让另一个线程看,却看到了一个很大的正数。 有的程序员让两个线程分别写入a和b两个变量,等线程结束后再读取a和b的内容,却诡异的发现:无论运行多少次,永远都看不到两个变量同时更新的结果。 有的程序员让一个线程不断循环等待一个变量为1,同时让另一个线程把值设为1。却发现前一个线程永远不会结束循环。 有的程序员让一个线程先写a再写b,让另一个线程先读a再读b,结果发现另一个线程会看到a的旧值和b的新值。 有的程序员不信邪,加进了第三个读线程,却发现在手机上跑有时候一个读线程会像上面一样,另一个读线程却完全正常。而在电脑上无论怎么搞都搞不出这种现象。 有的程序员发现/Od关掉所有优化之后程序又好了,换回/O2之后又跪了。
这下完蛋了!读不是读,写不是写,顺序全乱了!
谁动了我们的代码?
按路径看只有可能是编译器,操作系统和CPU!
是设计者们的魔法出了bug吗?为什么这群家伙没提醒过我们就修改了抽象,给了我们一记闷棍?
在程序员的逼问下,设计者们无奈地摊了摊手:我们当然可以维持老的抽象,但是那样太慢了!
于是,打着性能的名义,数十年来一直稳定的抽象一夜之间塌了一个大洞,把顶层的程序员们摔得头破血流。
随着旧抽象的坍塌,新的抽象必须尽快被建立起来。不然程序员就必须得直接和编译器与CPU打交道,就得精通各种细节才能完成基本的工作,还会对更新版本退避三舍——天知道这个版本会多出什么要新考虑的细节!
一个语言的内存模型,就是对内存的抽象建模。程序员只要基于内存模型的保证编写并发程序,就不需要害怕编译器和CPU给他们惹麻烦。
第一部分:并发编程中的基本问题,及其来源
在引入内存模型前,我们先总结一下先前提到的诡异现象和他们背后的问题,再说说这些问题是谁造成的。
前面提到的种种现象,其背后的问题都可以归入两个大类:原子性(Atomicity)问题和访存顺序(Memory Ordering)问题。
原子性问题

原子性问题,指的是高级语言中的内存操作语句(自增,赋值)与硬件操作失配所造成的问题。高级语言中的一条语句,可能会被编译器用几条机器指令实现。一条机器指令也可能会被CPU拆成几个操作进行。而线程间交错执行的粒度并不是高层语言中的语句,而是CPU的操作。这和程序员想的不一样,所以就引发了原子性问题。
之所以这么干,可能是为了性能,也可能只是因为底层没有直接实现这个功能的指令:32位CPU可能不支持用一条指令操作64位数据。机器的总线可能只有32位长,操作一个64位数据需要拆成两次才能执行。
举两个例子:i++可能实际上对应着三条机器指令:把i从内存取到寄存器中,自增寄存器,再把寄存器内容写回。假设i是一个64位的变量,i=-1可能实际上对应着两条机器指令:把i的低32位置为全1,把i的高32位置为全1,只要这两条指令间插进去一个读,那么就可以看到低32位全1,高32位全0,当然对应一个大正数。
对了,单核处理器不能从原子性问题中保护你,因为操作系统会对线程进行抢占式调度。线程可能会在i++中间的某个操作被操作系统暂停,然后让另一个线程使用这个处理器。如果另一个线程也进行i++就还是会有问题。
访存顺序问题
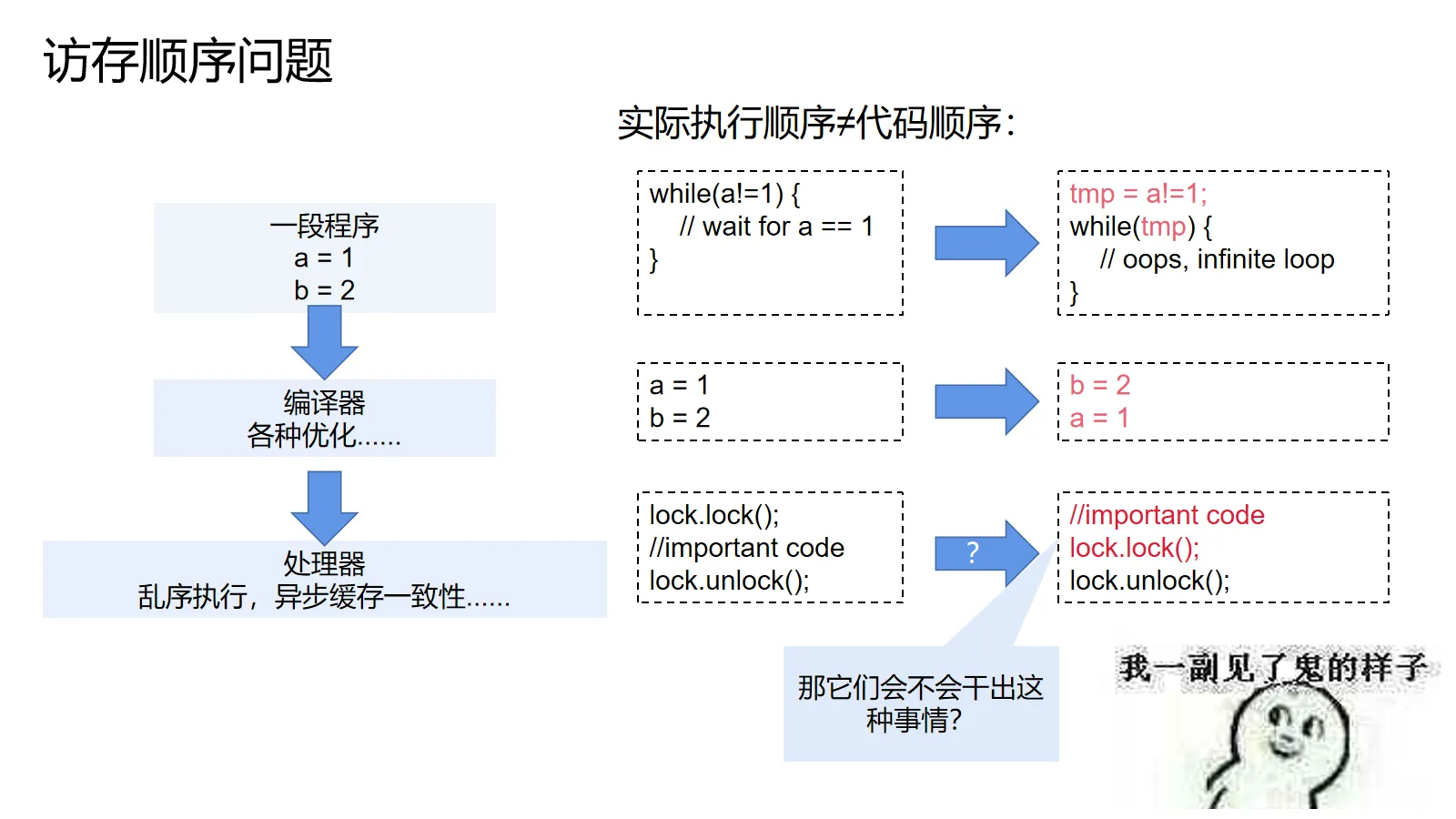
访存顺序问题,指的是机器实际上执行的内存操作顺序和程序中的顺序不一致所造成的问题。编译器可以随心所欲地重排,消除甚至预执行你的赋值语句和内存访问,处理器也有乱序执行和缓存系统来打乱机器指令中的访存操作。所有这些变换都基于单个线程/处理器核进行考虑,所以不会改变单个线程内部的执行结果(as-if-serial语义),但是一旦涉及跨多个线程间的共享状态,事情就变得有趣了起来。
之所以这么干,还是为了性能。编译器需要进行公共表达式提取避免重复计算,处理器想要缓存一致性,同时还不想等一致性协议完成。如果要保证不会改变多线程/多处理器的情况下的执行结果,那么很多像这样的常见优化就都做不了了,或者做起来要进行非常复杂的分析。
举个例子:假设我们有个不断循环等待a==1的循环。在编译器看来,这个循环条件的求值可以提前进行的。因为在单线程场景下,没有语句会在循环等待a的时候修改a,所以编译器开心地把条件提到了前面,砍掉了“不必要”的内存访问。然后这段代码跑起来的时候,只要一开始的时候a不等于1就会变成死循环。
仔细想想,访存顺序问题其实非常恐怖:见上图最下面的例子,既然编译器和CPU可以随意调换操作的顺序,那谁来保证加锁操作不会和互斥区里面的代码调换顺序呢?要是发生这种事情,那么我们就算用锁也没法躲开这些问题!(当然,内存模型会保证这种惊悚的事情不会发生)
单核处理器可以从CPU引发的访存顺序问题中保护你,但别忘了还有编译器!
注意:抓住重排序
接上文所说,编译器和CPU可以进行非常复杂的优化。我们当然没法一个个地了解这些优化会产生什么影响,但是我们可以认为它们等效于对访存指令进行重排。只要站在重排的角度,就可以解释(绝大部分,x86和RISC-V上是所有)优化对访存顺序造成的影响。
延伸:与可见性,有序性问题的关系
有些文章会把没有及时读到其它处理器写入的新值叫做可见性问题,把内存操作不按程序顺序进行叫做顺序性问题,还有些文章会把可见性问题归给CPU,有序性问题归给编译器。
我认为把两个问题合并起来,用改变内存访问顺序的思路去思考,统称为访存顺序问题更加简单。
小结:谁动了我的代码
原子性问题和访存顺序问题是编写并发程序,尤其是无锁并发程序时必须密切注意的问题。不妨称它们为并发编程的基本问题。
原子性问题(一条语句不等于一条汇编): (诱因)
- 编译器:在高层语句无法和CPU指令集直接对应的时候,会用多条指令实现这条语句
- CPU:在总线长度无法支持对应长度的读写时,一条指令可能会对应多个内存操作 (爆发点)
- 操作系统:抢占式调度会中断代码运行,导致写线程的写没有运行完成就开始运行读线程的读
- CPU:多核CPU的操作是同时发生的,交叉执行的粒度是内存操作,而不是语句
访存顺序问题(代码顺序不等于执行顺序): (诱因)
- 编译器:编译器可能会出于优化的目的而调整代码运行顺序
- CPU:CPU可能会为了性能而乱序执行或者异步执行缓存一致性协议,甚至放弃缓存一致性 (爆发点)
- CPU:在多核场景下程序对操作顺序有所要求(先检查这个变量,如果为1就认为别人完成工作了,开始读那个变量)
值得提醒的是,只要保证在一个核上运行,同时线程采取非抢占式调度,就可以避免写或者读被中途打断,就可以当原子性问题不存在。(操作系统的信号机制就是另一码事了…)
此外,假设编译器不会跨非抢占式调度中断点进行优化(基本都满足这个要求),那么只要在一个核上运行,就可以当可见性问题不存在。这也是为什么你不大可能看见基于单线程事件循环用协程(或者类似协程的东西)搞并发的地方(例如JavaScript社区/Python社区)有人操这个心。
第二部分:内存模型(民用版)
和引文所说的一样。简单来说,内存模型是关于内存的一系列契约。内存模型会规定哪些操作是原子的,哪些操作必须看见哪些操作的结果(大致相当于哪些操作不能被重排到哪些操作的后面)。只要面向这个契约编程,我们就不需要害怕编译器和CPU会搞坏我们的代码。
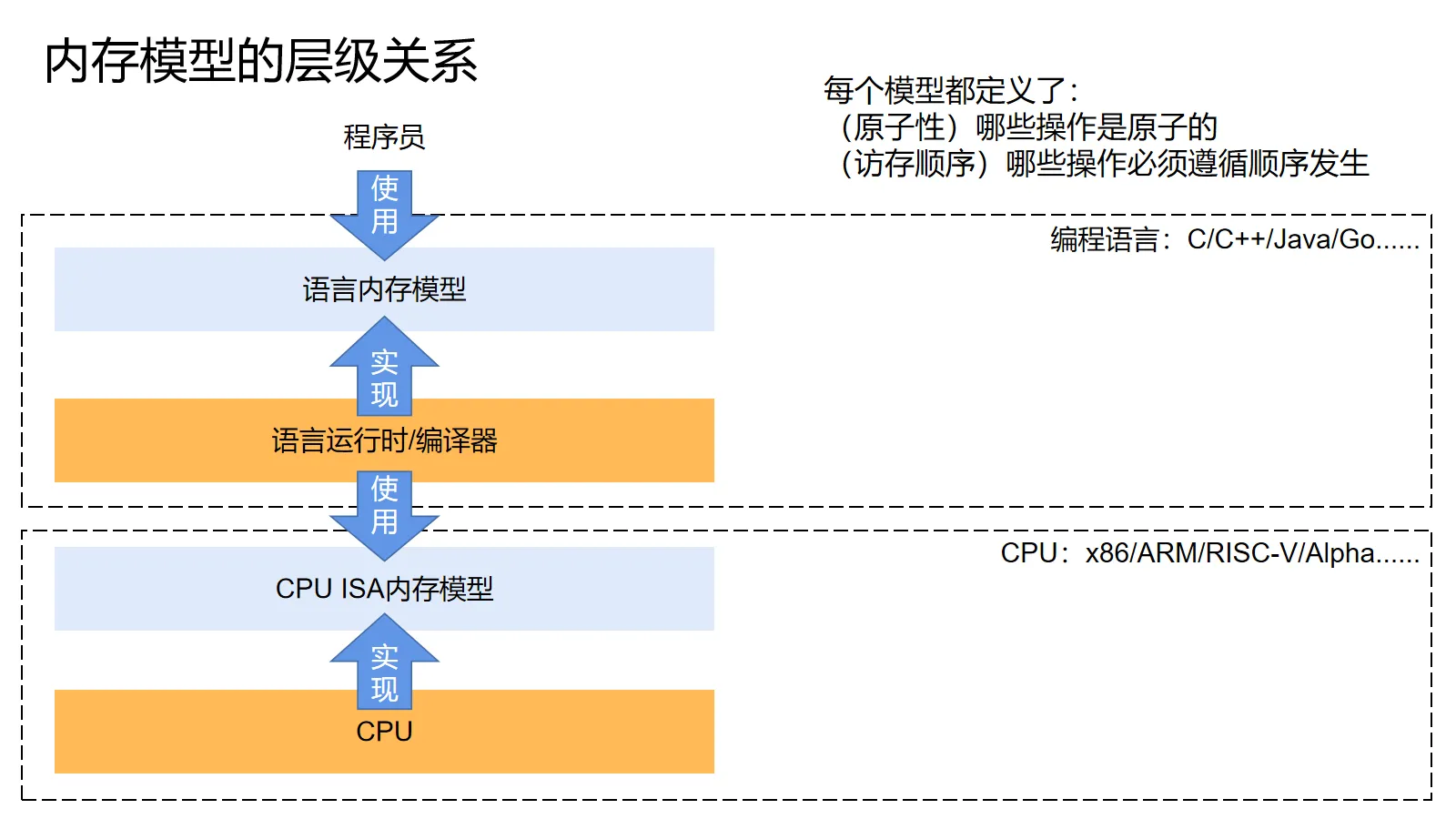
整个计算机体系是分层级的,所以内存模型也自然是分层级的。处理器的设计者们在设计ISA的时候就会定义处理器的内存模型,然后保证处理器里的各种优化不会违反它。程序语言的设计者们也会定义好语言的内存模型,然后保证编译器的优化不会破坏它,同时使用处理器内存模型提供的契约来保证处理器也不会破坏它。
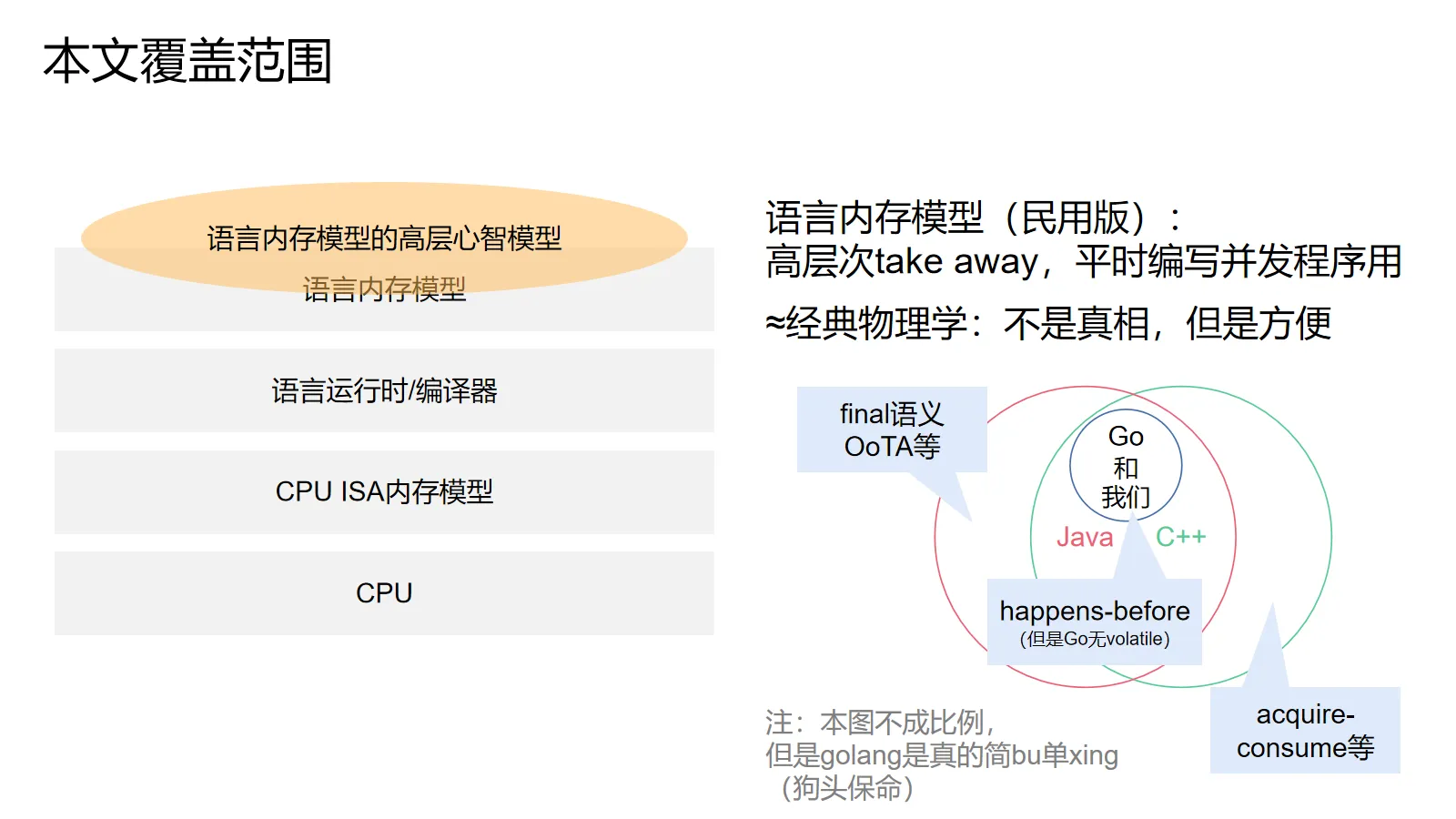
本文的重点在于介绍语言的高层心智模型,也就是编写并发程序的时候可以简单用起来的工具。概念上相当于经典物理学——它不是真相,但是平时真的非常好用。
尽管我在举例子的时候主要使用Java(内存模型面成八股文的估计也就Java了),但本文所介绍的高层次概念模型应该对主流编程语言都有效——无论是Java,还是C++,还是Go。本文介绍的内容大致是Golang内存模型的超集,Java和C++内存模型的子集。
此外,本文将通过三个层级的模型,由易到难,依次递进地进行介绍。它们应该都是对的,但是越往后越接近规范本身。
注意:Java volatile & C++ volatile
接下来的文章我们会大量使用Java的volatile来进行举例,当我说volatile的时候指的是Java的volatile,而不是C++的volatile关键字。
Java volatile在C++中的对应是std::atomic(名字确实很奇怪,毕竟这个类身兼二职——既负责原子性又负责访存顺序),而不是volatile关键字。volatile关键字在C/C++中相当于“仅编译器Java volatile”,它能禁止编译器进行指令重排,但对CPU没有效果。
延伸:语言内存模型发展历史与展kou望hai
Java是内存模型领域的先驱,它是主流语言中最早拥有内存模型的语言。Java最早的内存模型(基于工作内存-主内存)提出于1995年,然后很快被发现有一大堆的漏洞。为了修补这些漏洞,Java社区组织了一群大牛,提出了JSR-133,并在J2SE1.5版本合入Java语言规范。JSR-133将整个内存模型砍掉重练,并提出了今天的Java内存模型(基于happens-before)。
在Java修订完毕之后,C/C++也学习Java,在C/C++11中提出了自己的内存模型,并在后面的版本中都有所调整和修改。而再后面的新语言(Rust/golang/javascript(对,js也有这玩意儿))基本都在学习Java/C++。
即使经过了近25年的发展,编程语言内存模型仍然是一个发展中的领域,各个语言的内存模型基本都还有坑。C++的内存模型是主流语言中最复杂的。Java有学习C++的迹象(Java 9 VarHandle,但是内存模型还没做对应的更新)。Golang决定躺平(happens-before意思一下,然后告诉开发者要么用CSP模型要么上锁),Rust还在举棋不定,但估计会抄C++。
合着大家都在抄C艹,C艹牛逼(破音)!
关于原子性问题

首先,这三个模型在原子性问题上的描述都是一致的:我们一般可以认为64位及以下变量的赋值和读取是原子的。其它所有操作(自增,自减等等)都需要使用专门的原子操作。具体怎么做请参考你所使用语言的原子操作库。
第一级:SC-DRF
我不要你的骚操作,我要下班!
—— 改自林彪
设计编程语言内存模型的一大重点就是平衡性能和使用难度。既要能允许各种优化,还要不让程序员看了想转行。
那么,从使用难度着手,程序员想要什么?
童话:顺序一致性
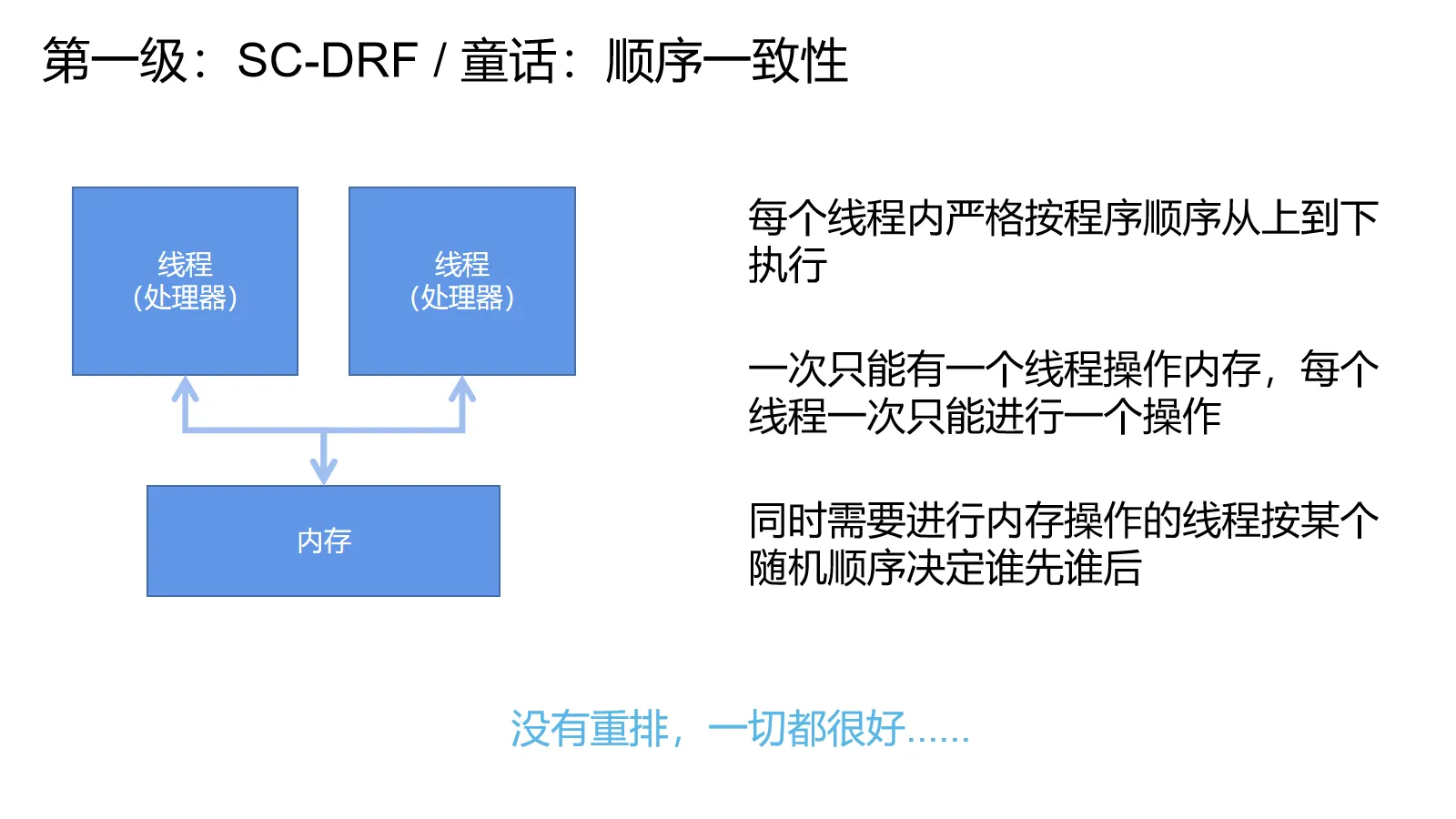
程序员当然想要最符合直觉的行为.
就像引子中提到的那样,每条线程从上往下执行,线程之间的操作交叉进行,没有什么乱七八糟的重排问题。
这个心智模型叫做顺序一致性,由大名鼎鼎的Leslie Lamport正式提出。
童话(修订版):SC-DRF
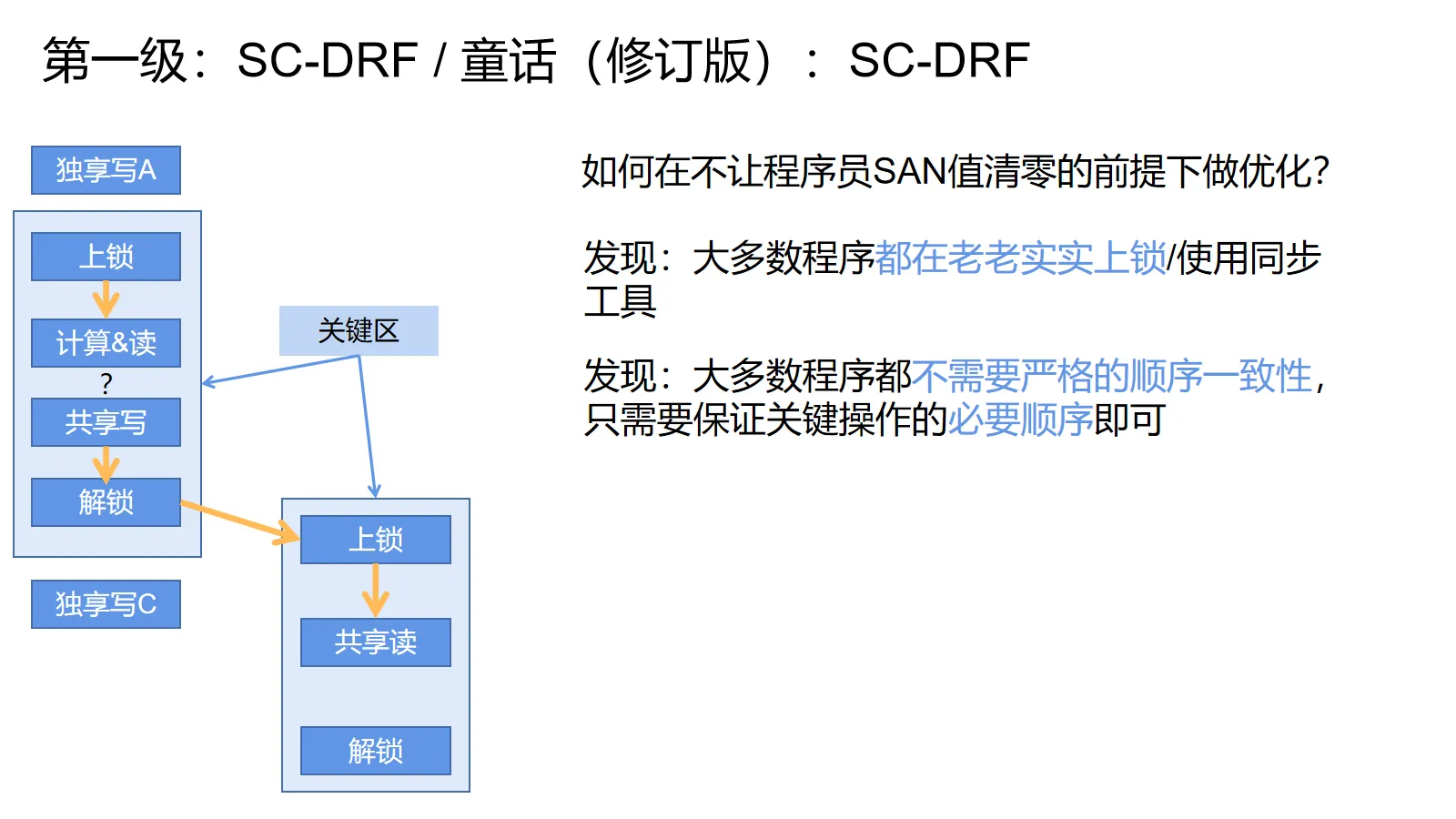
顺序一致性虽然好,但是性能不行。随心所欲地重排性能很好,但是会让程序员崩溃,怎么办呢?
在经过一系列的摸索和斟酌后,专家们发现:
- 大多数程序都在乖乖地使用同步工具(例如锁和并发数据结构)
- 大多数程序都不需要绝对的顺序一致性,只需要保证关键的顺序即可
举上图的例子,对于用锁保护的变量,我们只需要保证上一个进入关键区的线程在里面的所有操作对下一个进入关键区的线程全部可见。里面的计算过程和各种读写的顺序是可以随意调整的。同时,对于外面那些操作,由于这里它们只会对线程私有状态(只有这个线程可以访问到的状态)进行操作,进行重排也无妨。
利用这一点,专家们提出了SC-DRF的概念。下面给出的所有心智模型,以及语言标准都保证这个概念有效。
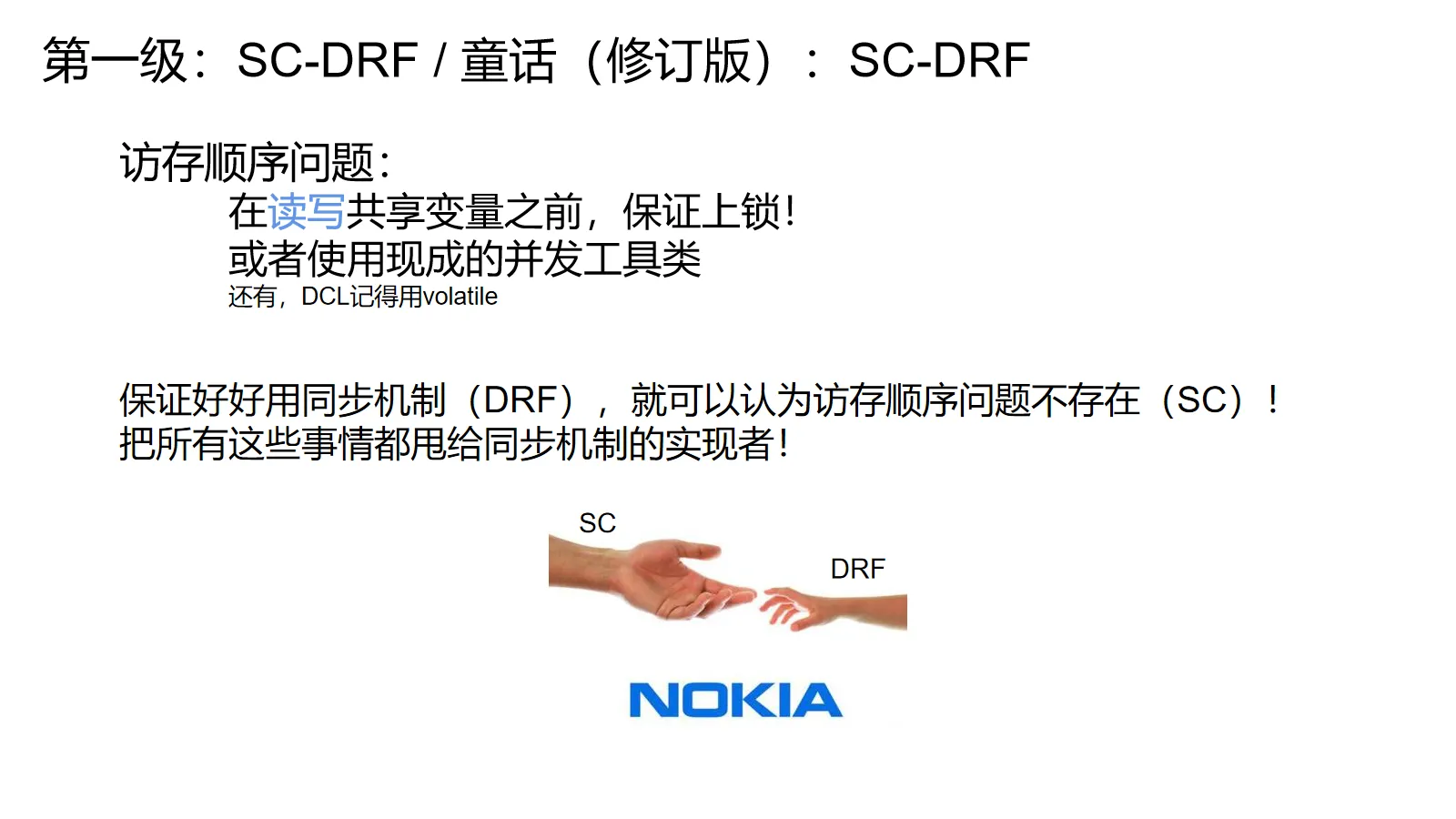
SC-DRF,顺序一致,无data race。只要程序员使用同步机制(不只是锁,具体定义更加宽泛)来保证自己的程序没有data race(可以译作数据争用?),设计者们就保证提供顺序一致性的幻觉。
简单来说,只要你乖乖给共享变量读写(读也要)上锁,或者使用现成的并发工具类,或者把所有跨线程共享的变量都用volatile标起来。你就不需要操心访存顺序问题——这些工具的实现者们已经替你操心完了。
尽管这样写出来的程序性能不一定是最优的,而且用锁很多时候也有需要额外考虑的问题(死锁等等),但是这么搞就能规避这个非常恶心的问题。
按道理来说,除非你需要编写并发工具类(例如无锁数据结构)或者进行极限优化,否则一般记住SC-DRF就够了。
第二级:acquire-release
和人见面说你好,与人告别说再见 —— 做人常识

一旦我们决定不使用锁和现成的并发工具,我们就必须直面访存顺序问题。一个考虑这个问题的常见思路是使用acquire-release语义,大多数语言的happens-before关系实际上都是为了实现这个语义。
acquire-release语义包含两种特殊的操作:acquire操作和release操作。只要一个线程(线程A)的release和另一个线程(线程B)的acquire配对,线程B acquire后面的操作就一定能看到线程A至少到release前的所有操作(例如线程A release前执行了a=1,线程B acquire到那个release之后读a就能读到1,除非线程A自己或者某个别的线程不讲武德,在A release后又修改了a的值)。
acquire操作一般包括并发数据结构的写,加锁和volatile读等。 release操作一般包括并发数据结构的读,解锁和volatile写等。
acquire-release模型可以类比成无菌室的传递窗:传递窗有两个相对的门,一次只能有一个打开。我们从一边把样本放进去,把门关上。关门这个动作会启动窗里的紫外线灯,进行杀菌。杀菌完后对面的门就会解锁,无菌室里的人就可以开门把外表经过杀菌的样本取出来。这样就能保证附在样本盒表面的细菌不会和样本一起进入无菌室。
对于acquire-release模型而言,我们(线程A)先对某个共享状态进行一系列的操作,然后关门(release),对面的人(线程B)只要等(配对的acquire)到门解锁了,就能把完好的数据取出来(线程B acquire操作后的操作能看到线程A直到release操作之前的所有操作)。
这么说可能有点抽象,所以我们来看点例子,顺便解释前面说的“配对”是个什么概念:
常见案例:安全发布
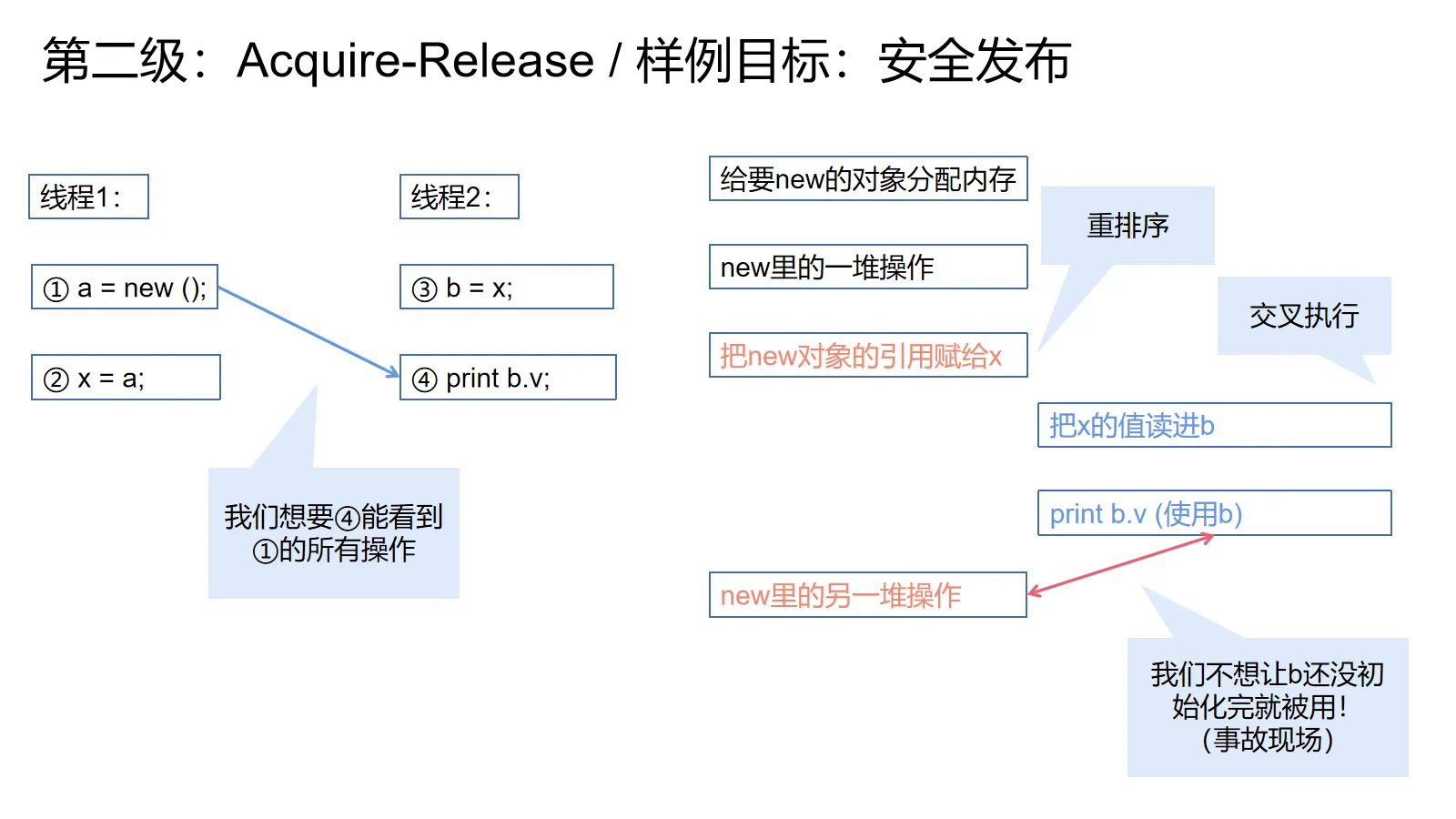
为了方便举例,我们接下来的例子都立足于安全发布(safe pulication)。
安全发布问题就是一个线程新建了一个对象,然后把这个对象发布给其它线程用。我们要保证其它线程拿到对象引用的时候,不会看到一个初始化了一半的对象。
举上图左边的例子,可能线程1new了一个非常复杂的对象,这个对象的构造函数里面有一大堆操作,然后会把一个特别复杂的值赋给v这个成员。然后线程1就把new的结果赋给了共享变量x。 而线程2通过x拿到了这个对象(也有可能拿的动作③在②前发生,那会拿到null,我们先不考虑这个),然后开始使用这个对象(步骤④)。
如果我们对编译器和CPU不作任何限制,它们就可能像上图右边一样,把②重排进①的构造函数逻辑里去,在完成构造之前就发布了这个对象。然后在交叉执行的推波助澜下,线程2读到了一个初始化到一半的对象。
我们下面的大部分例子就是为了避免这种事情发生。
举例:并发队列
既然我们用了传递窗来类比,最直观的例子当然就是对象传递:

并发队列入队可以理解为release(我们把对象放了出去),出队可以理解为acquire(我们把对象拿到了手里)。只要出队得到了入队的对象,那么这个出队和对应的入队操作就建立了关系。出队线程出队操作后面的操作(print)就能看到入队线程入队操作前面的所有操作(new),这当然包括被交换的对象的初始化操作。
看上面的例子,线程1先new了一个SomeObject,然后把它推进并发队列里,然后线程2会阻塞地获取这个队列里的元素(获取的时候没有就停下来等)。线程2的出队会读到线程1入队的对象,建立了关系,然后就能保证线程2的print操作能看到线程1的所有操作,这当然包括new,所以不会看到构造了一半的对象。
举例:volatile读写与锁
比起并发队列,volatile和锁解释起来要更微妙些:
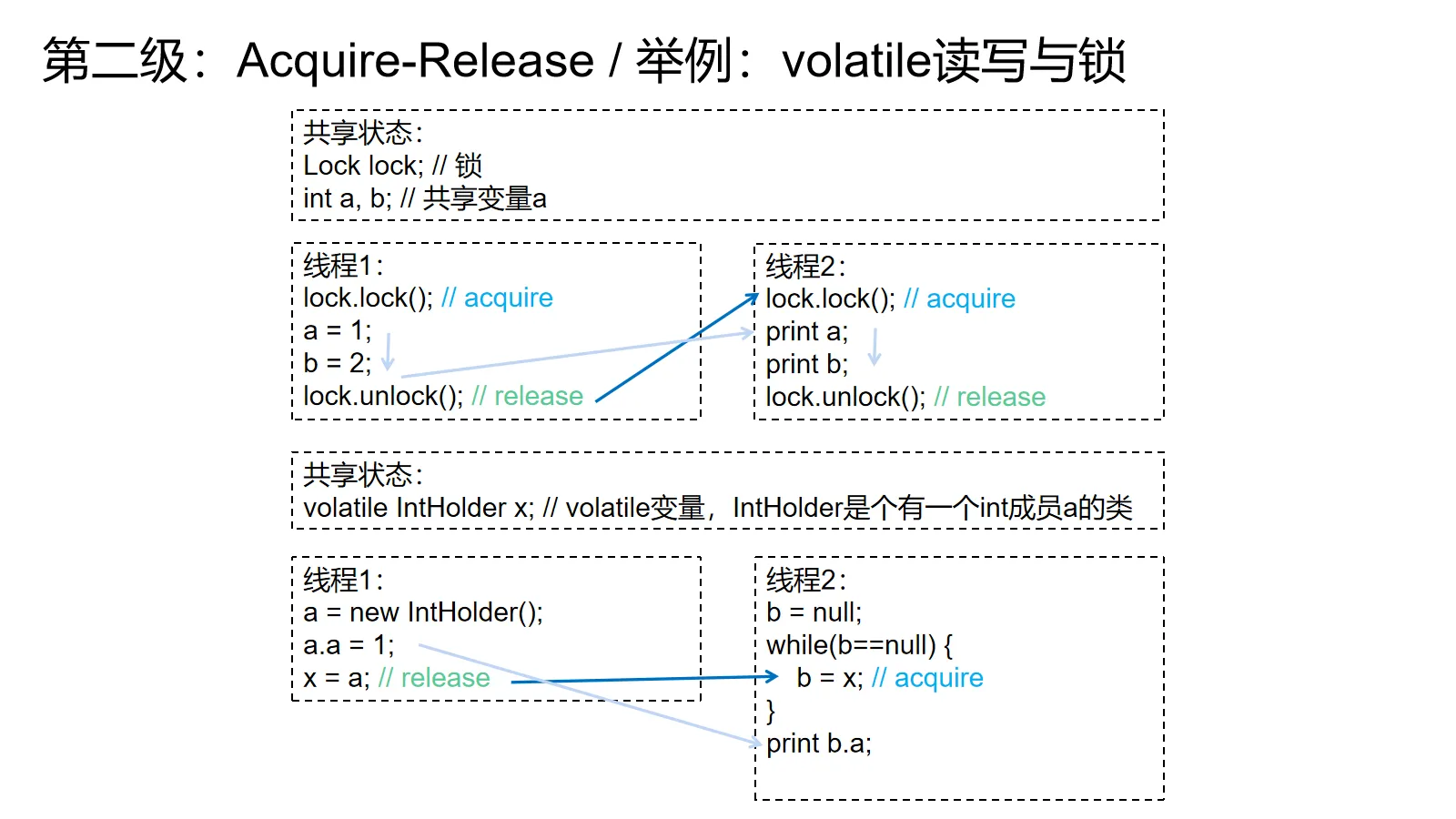
对锁而言,上锁可以理解为acquire,解锁可以理解为release。对一把锁的上锁操作会和这把锁前面所有的解锁操作建立acquire-release关系。一旦建立关系,那么这个上锁操作后面的操作就一定能看到先前解锁操作前面的操作。上锁操作和解锁操作之间的先后关系一般要靠锁保护的状态判定。
看上图上面的例子,线程1先上锁,分别给1和2赋值,然后解锁。线程2也是先上锁,分别读a和b,然后解锁。
如果线程2读到了a=1,那么我们就可以确信线程1的解锁操作和线程2的上锁操作建立了关系——要先写1进去才有可能读到1,所以线程1的关键区先于线程2发生,线程1的解锁先于线程2的上锁。线程2对b的读一定会读到线程1对b的写。
同理,如果读到了a=0,那么应该是线程2的解锁操作先于线程1的上锁操作(还没写),所以一定不会读到线程1的写。
对volatile而言,写是release,读是acquire。假设程序每次写入volatile的值都不一样,只要volatile读读到了volatile写的值,就能建立关系,保证可见。
看上图下面的例子,如果线程2的循环结束了,那么volatile读就一定读到了线程1的写,建立关系,保证可见性,print一定能看到线程1的赋值。
上面这些例子就是SC-DRF成立的原因——因为有配对关系,所以保证了可见性,所以只要乖乖用它们就不需要担心访存顺序问题。
举例:DCL
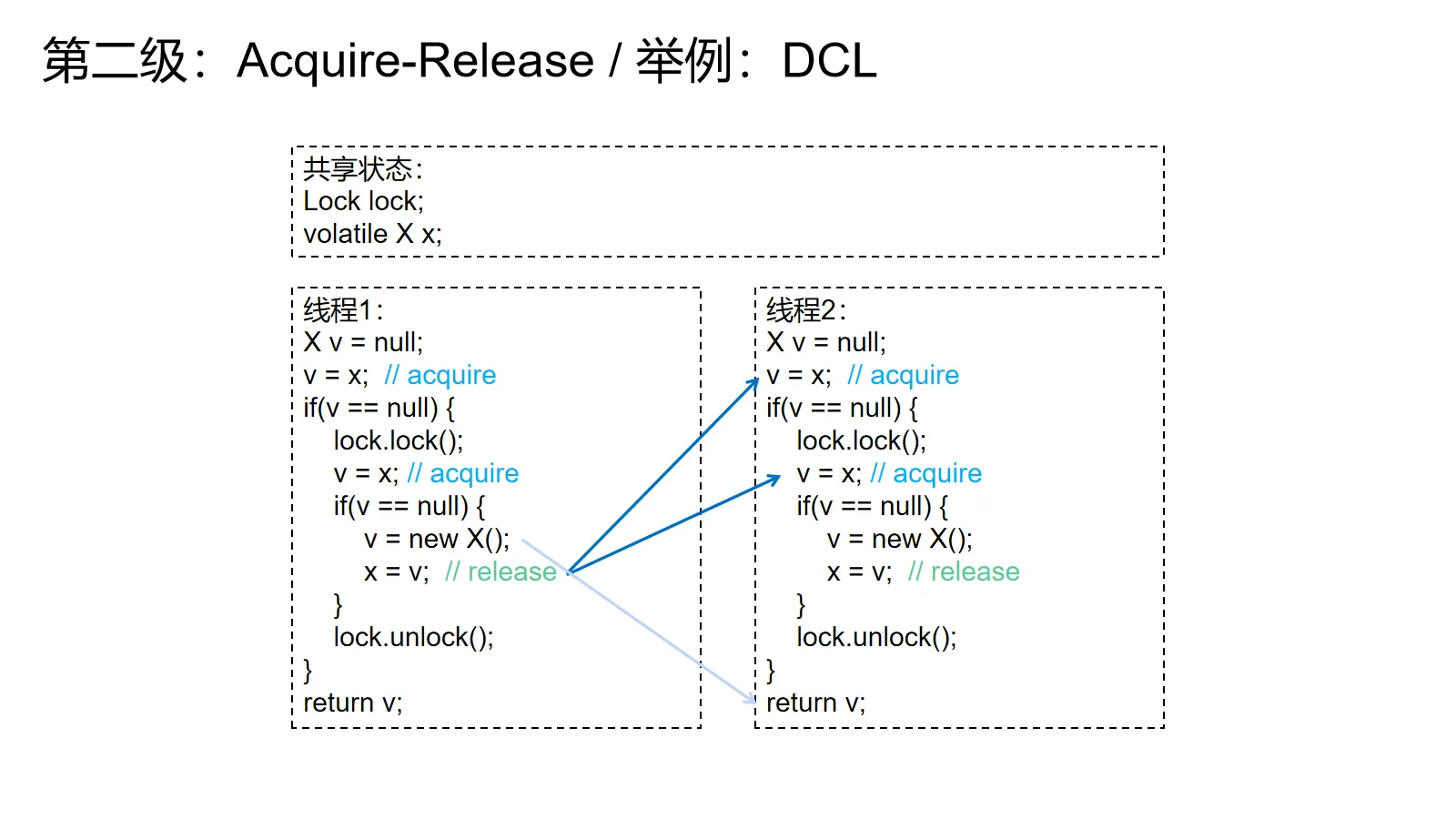
好了,看了这么多简单的例子,接下来举个日经点的例子——双重检查锁定(DCL)。
双重检查锁定,结合单例就是大名鼎鼎,面试被问烂的DCL懒汉式单例,下面我就直接称这东西为DCL了。
实现懒汉式单例最简单的办法就是用锁保护指向单例的全局变量,然后在锁里面检查全局变量为不为空,如果为空就新建一个对象然后赋给那个全局变量,否则就直接返回那个全局变量里的对象。
这里为了避免这把锁的开销,我们在上锁之前预先检查一下全局变量为不为空。如果不为空就直接拿对象返回。这样可以在全局变量不为空的时候(大多数情况,毕竟只会初始化一次)避开这把锁。需要注意的是锁里面也要先检查一下全局变量为不为空,因为可能会出现同时多个线程检查到空然后同时试图拿这把锁来做构造的情形。在这种情形下应该只有第一个线程真正执行构造,后面的线程应该全部返回第一个线程构造出来的结果。
上图的例子和常见的DCL有个小区别,最后的return并没有return x,而是复用了前面读到/构造出的x。这样搞既能节约一个volatile读,还方便我解释。
根据前面例子的解释,volatile读是acquire操作,volatile写是release操作。假设线程1是负责构造的线程,那么线程1就会执行new后面的volatile写。线程2要么会在锁外的读读到线程1的写,要么会在锁内的读读到线程1的写(否则就是线程2负责跑构造逻辑了)。由于volatile读读到了volatile写的值,所以建立了关系,线程2一定会看到构造完整的对象。
这个配对关系就是为什么即使看起来有锁也要给全局变量加volatile的原因,锁只能保证抢着构造的线程之间的可见性,不能保证跑构造逻辑的线程和从锁外读拿到对象线程的可见性。
历史:DCL was broken
DCL其实在内存模型出现之前就存在了,可惜那个时候人们只认识到了锁的互斥作用,但没认识到它们对可见性(访存顺序)的保证。 这导致早期的DCL实现都会有一些编译器/CPU特定的灵异问题。直到内存模型(Java据称是JSR-133修订)出现之后,DCL的正确性才得到了保证。
追加:DCL has better alternatives
《Java并发实战》宣称,DCL是为了规避JVM性能低下的锁机制和缩短启动时间提出的。由于DCL在初始化完毕的情况下完全不会用到锁,所以没有性能问题。这本书同时认为DCL所要解决的问题其实已经不再是问题了——现代JVM的锁机制速度不慢,同时启动速度也在逐渐变快。
对于坚持想要懒汉式单例的人,它也给出了替代方案,即利用类加载机制来实现懒加载和线程安全(见书程序清单16.6)。
对于C++而言,懒加载线程安全单例更加简单,直接在函数里使用static变量即可。如果你觉得不满足还有call_once这类工具等着你。
可能这玩意儿现在还在问就是因为可以引出内存模型吧。
实现方案
好了,你可能会觉得有点懵。因为我先前说的并发两大问题是原子性和访存顺序。但是我在讲内存模型的时候又悄悄走私了一个可见性的概念进来。它们是啥关系呢?
这是因为语言内存模型一般不会通过允许或者禁止重排来定义内存模型,那是CPU内存模型的常见定义方式。语言内存模型是基于可见性的,即对于一个读操作而言,哪些操作对它是可见的,是能读到它们的值的。
为了方便建立可见性和重排之间的关系,我会讲讲它们是怎么对应的,顺带提一嘴实现。
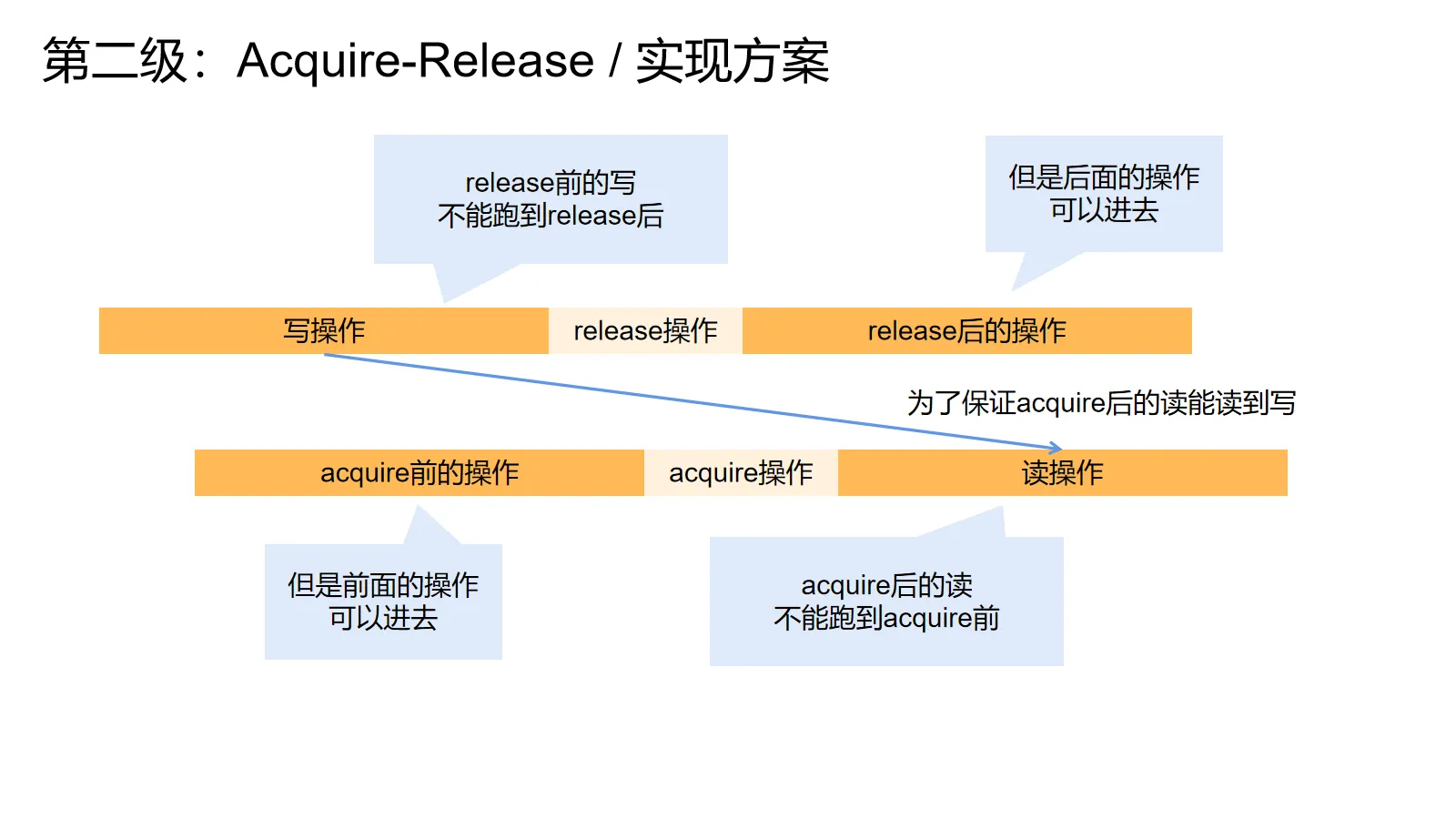
假设线程1有一个acquire操作,线程2有个release操作。为了保证在配上对的时候线程2 acquire后的操作一定能读到线程1 release前的所有操作,我们必须保证线程1里的写操作不能跑到release后面,线程2的读操作不能跑到acquire前面。不然就会发生在安全发布例子里的事故。
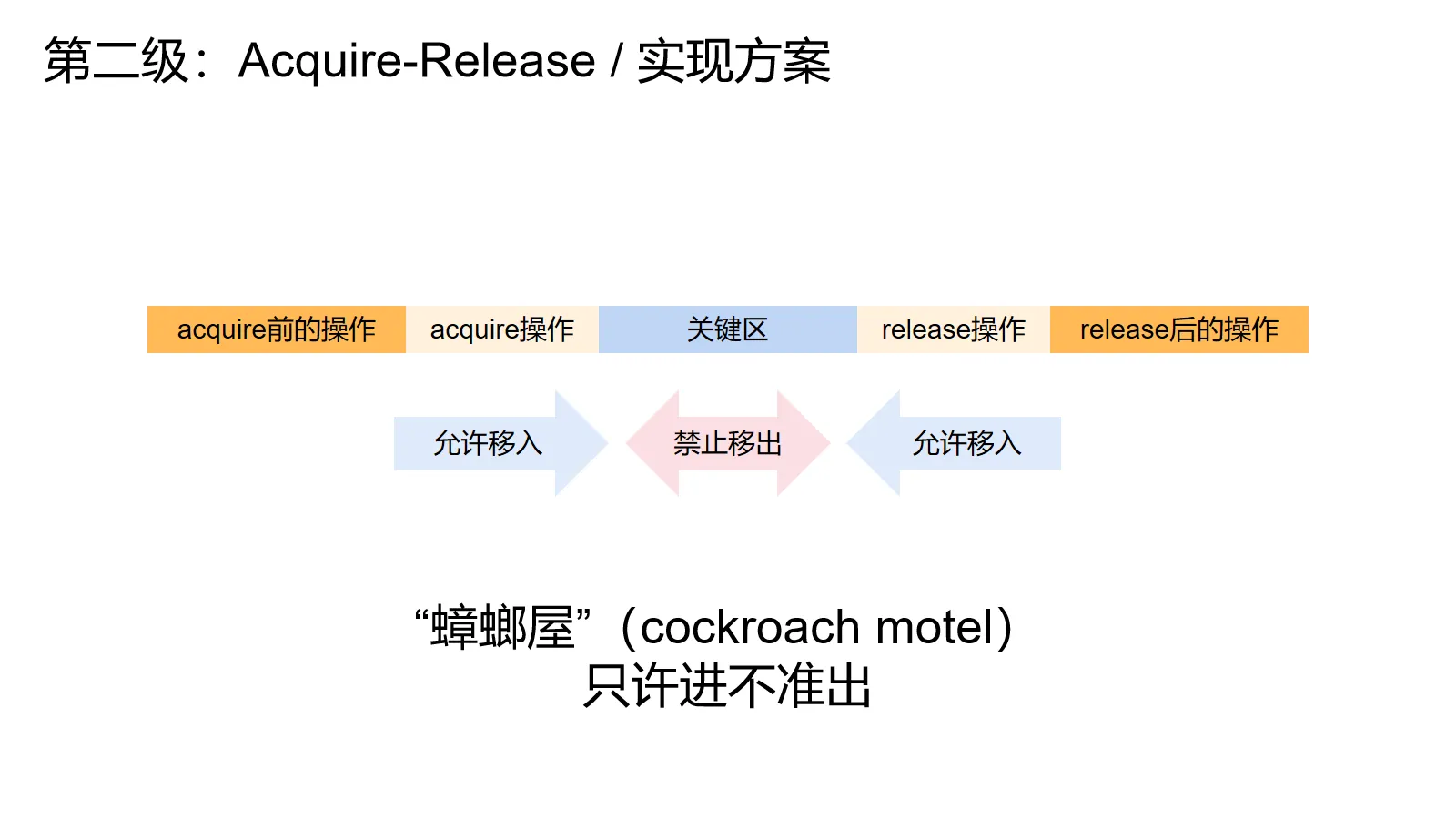
稍微扩展一下,把acquire视为加锁操作,release视为解锁操作。我们禁止读写操作跑到release的后面,acquire的前面,这样就保证了关键区里的操作不会逃到关键区外面,引发一堆奇怪的灵异现象。
需要注意的是,这个模型不禁止acquire前面的操作跑到acquire后面,release后面的操作跑到release前面。就像一个蟑螂屋一样,允许蟑螂从两头进去,禁止里面的蟑螂跑出来。所以acquire-release模型的一个诨名就叫做蟑螂屋(cockroach motel)模型。
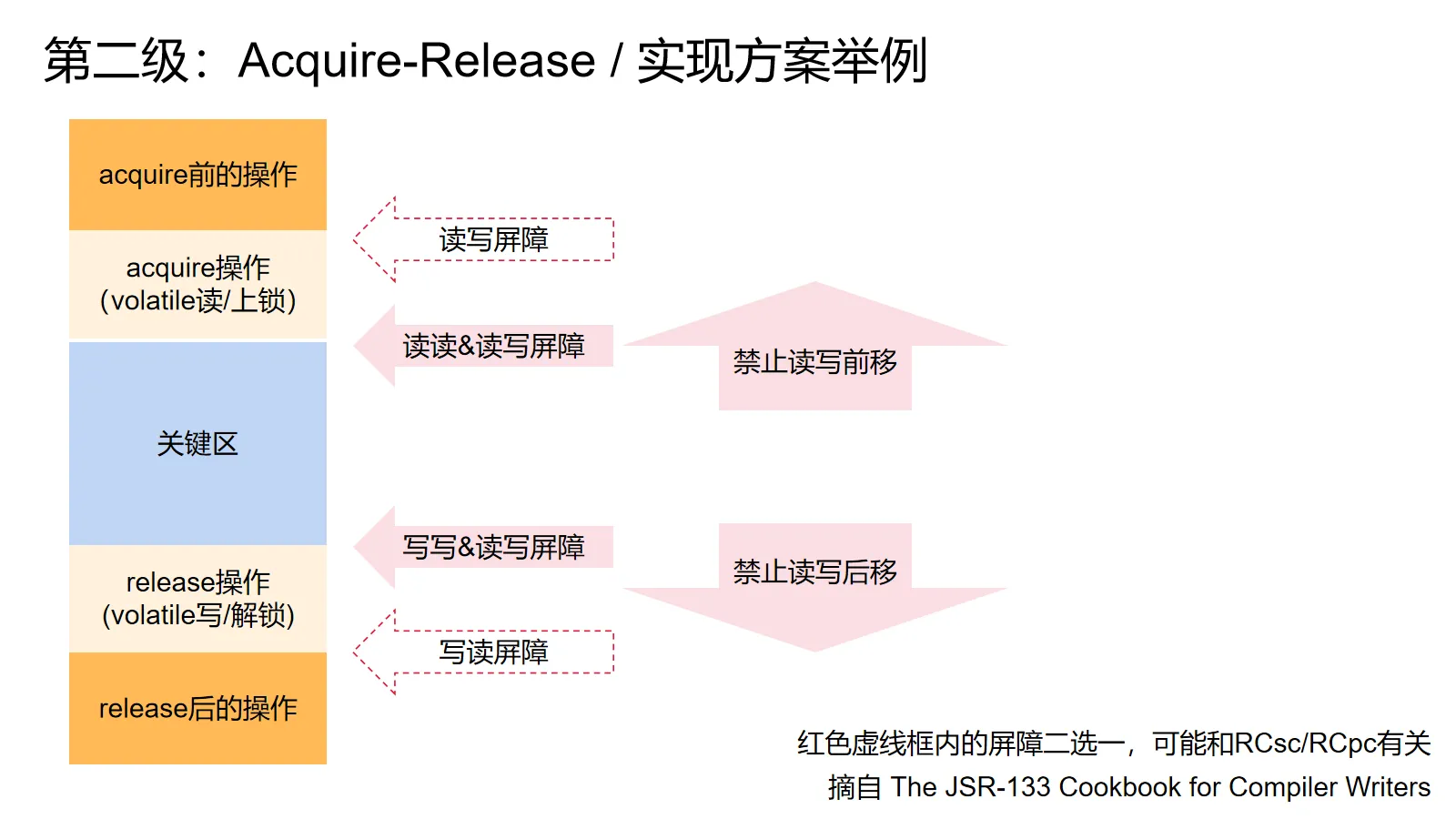
那么要怎么实现呢?参考The JSR-133 Cookbook for Compiler Writers(讨论如何实现Java内存模型的一份参考资料):
首先,编译器必须禁止一些优化(例如公共表达式合并)来避免违反上面的要求。同时也会产生一些特殊的机器指令来强制CPU不要违反上面的要求。
这些特殊指令叫做内存屏障,一般按照禁止的重排进行命名,例如读写屏障会强制屏障指令前的读先于屏障指令后的写完成,诸如此类。
把acquire操作看作volatile读,release操作看作volatile写,我们就知道要插入什么屏障来满足上面的要求了:acquire是一个读,后面的操作不能跑到前面去,所以acquire的后面要插读写和读读屏障,release是一个写,前面的操作不能跑到后面去,所以release前要插读写和写写屏障。
除了这些屏障之外,我们还有一个额外的屏障要插,我猜想这是为了满足acquire-release模型的RCsc变体的要求,不然就会变成RCpc。
当然,实际上的实现不止这么简单。首先volatile写不需要读写屏障,因为volatile写不是解锁操作,不需要保证前面的读操作不会跑后面去,现代JVM也会进行各种花式的消除和合并来避免产生内存屏障指令(毕竟屏障要求CPU等待前面的指令先完成),细节除此之外,不胜枚举。
还有,尽管语言规范实际上要求实现的是happens-before模型,我认为从它的高层抽象,也就是acquire-release模型来讲会更加容易些。
第三级:happens-before
programmer: spec, can we have sequential consistency? spec: we have sequential consistency at home! sequential consistency at home: —— 改自外网烂梗

在有了acquire-release打底之后,我们就可以揭开幕布,进入真正写在语言标准里的happens-before模型了。你可能会觉得它和前面的acquire-release语义很像,实际上,happens-before模型就是上面那个acquire-release模型的严格定义版。
happens-before模型由这几点构成:
- happens-before模型提供了一些特殊的操作,称为同步操作
- 同步操作之间可以建立先后关系,只要一个同步操作A先于另一个同步操作B,就说A happens-before B
- 每个线程内的所有操作按照控制流顺序构成happens-before关系
- happens-before满足传递性,如果A happens-before B,B happens-before C,则有A happens-before C
一个操作能看见happens-before它的所有操作,也就是说假设没有happens-before没覆盖到的写操作,读操作会从在happens-before关系中离它最近的同变量写操作中取值。
好了,接下来要做的就是举例子说明这摊玩意儿到底是啥意思,以及讲清楚同步操作之间的先后关系。
Happens-Before 八条规则
按照《Java并发实战》的描述,Happens-Before顺序主要由下述八条规则构建而成:
程序顺序规则:每个线程里的操作happens-before这个线程里控制流顺序后面的操作
传递性规则:A happens-before B,B happens-before C,则有A happens-before C
线程启动规则:对一个线程的start方法调用happens-before这个线程的所有操作
线程中断规则:对一个线程的interrupt方法调用happens-before这个线程检测到这个中断(例如isInterrupted或者InterruptedException)
线程终止规则:对一个线程的所有操作happens-before所有检测到这个线程终止的操作(isAlive返回false,join方法返回等)
监视器锁规则:对一把锁的解锁操作happens-before其后对这把锁所有的加锁操作
volatile读写原则:对volatile变量的写happens-before其后所有对该volatile变量的读
Finalizer原则:一个对象的构造函数里的所有操作happens-before其finalizer里的所有操作
由于Finalizer属于已经被废弃的特性,这里就不作介绍了。接下来我们从易到难分三类介绍这些规则:我们先介绍传递性规则和程序顺序规则,再介绍线程的启动,中断与终止,最后介绍监视器锁和volatile读写原则。
此外,语言标准库里的并发工具(例如java的java.util.concurrent)也会提供happens-before保证,详情请参考它们的文档。
程序顺序与传递性
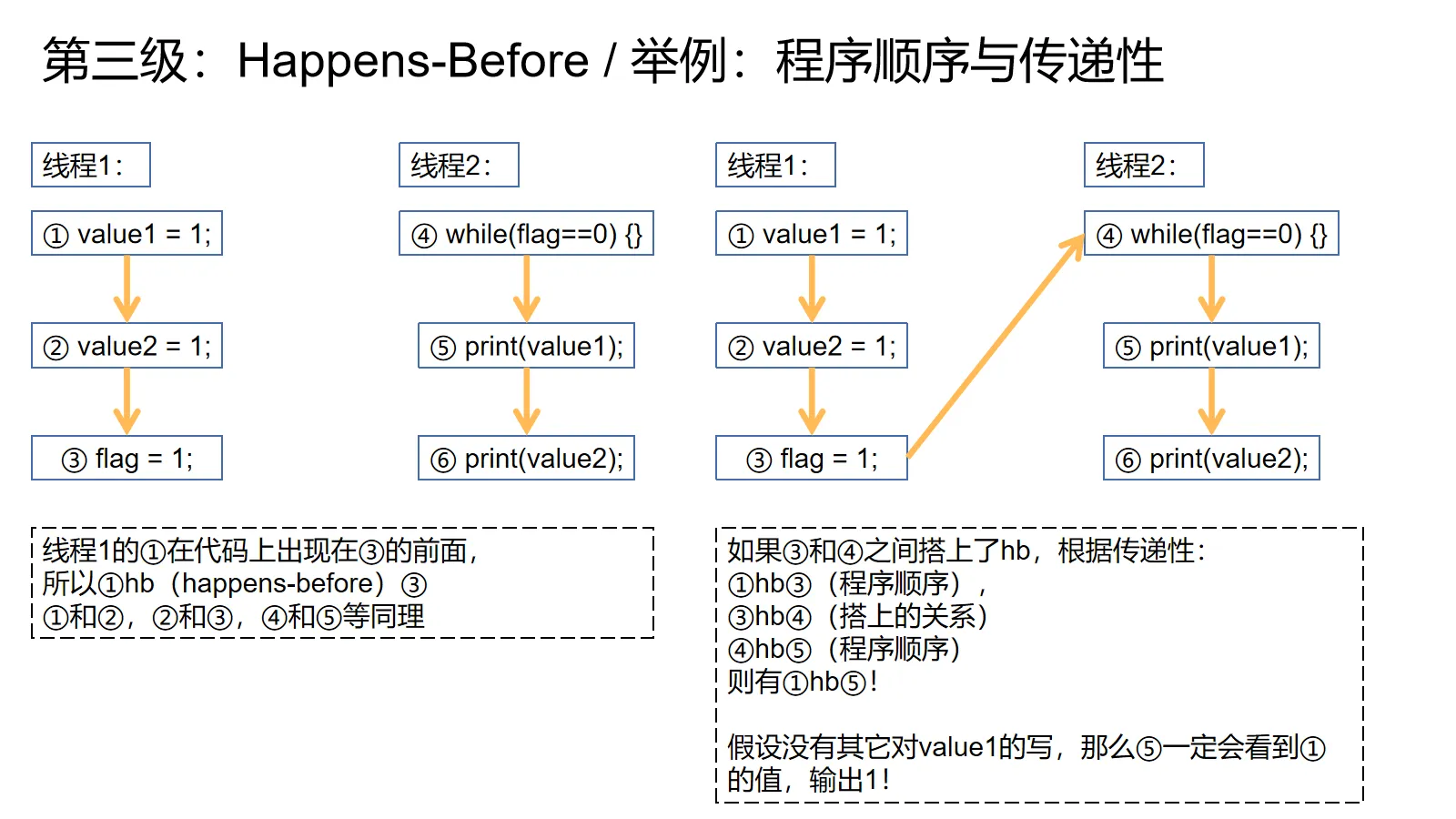
程序顺序规则就是指一个线程中,先执行的操作happens-before后执行的操作。上图左边的①由于在③前面出现,所以①hb(happens-before的简写)③。
传递性规则,顾名思义,就是给定①hb②,②hb③就有①hb③。
这两点可以看作是为了实现acquire-release语义。只要两个线程中间依托某种同步操作建立一条hb的“桥梁”,就可以横跨过去,让桥梁终点(acquire)后面的所有操作能看到桥梁起点(release)前的所有操作。详情请看上图右边。
线程启动,终止和中断规则
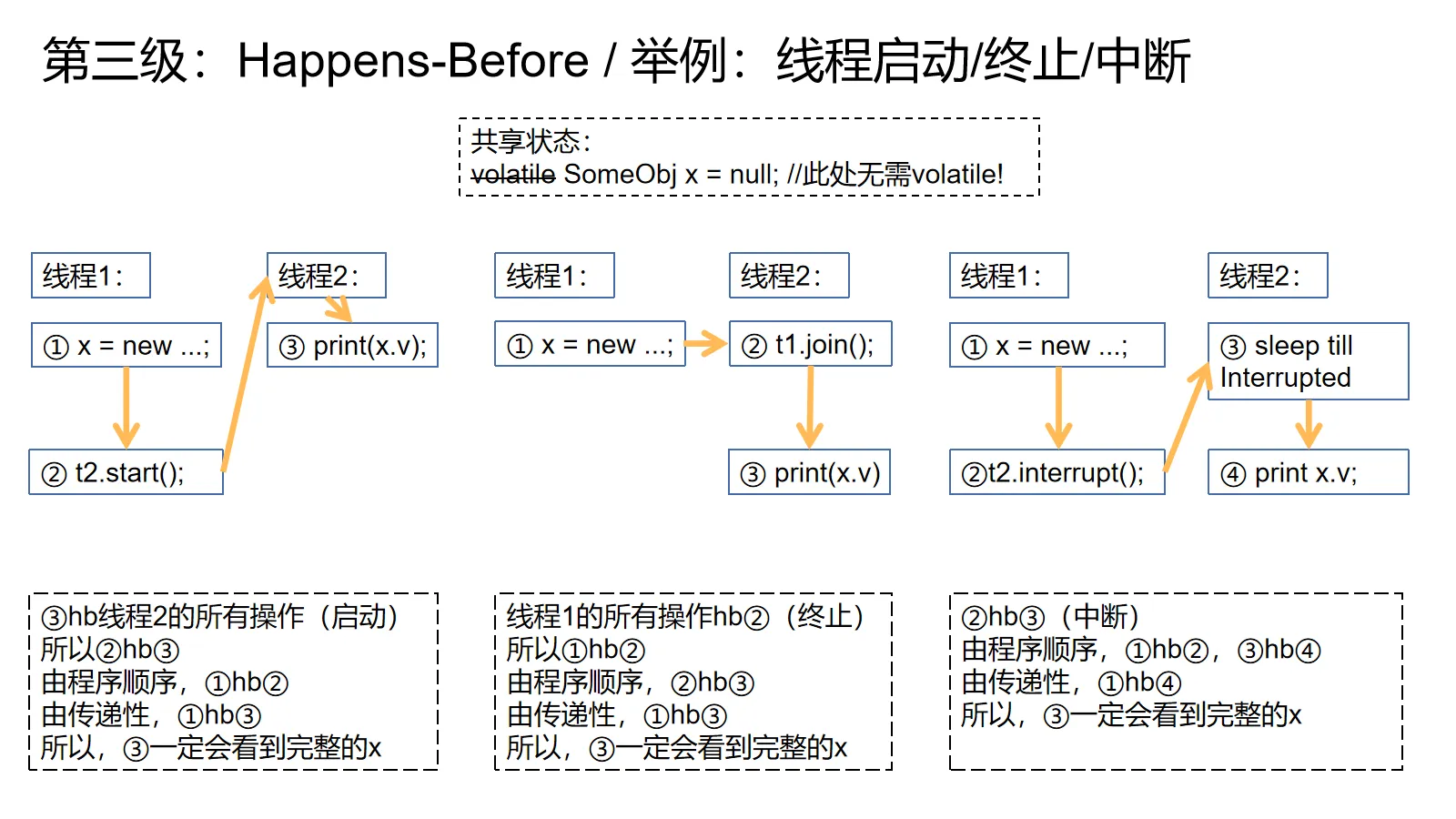
线程启动/终止和中断规则是最好理解的,因为同步操作之间的先后关系很好理解:启动一个线程hb这个线程的所有操作,一个线程的所有操作hb通知其他线程这个线程终止的操作,一个线程发送中断的操作hb目标线程得到中断信号的操作(抛异常或者检查isInterrupted)。
上图提供了三个例子,由于图已经有所解释,这里就不赘述了。不过要强调一点,由于我们已经开始使用线程的规则了,所以上图的共享变量无需volatile!
启动规则最直接的用法就是在线程启动前先做一堆初始化工作,然后启动线程。只要我们保证不再改动共享状态,所有的共享状态就都可以不加volatile。终止规则同理,如果一个线程计算完成了,把结果放在了某个对象里,然后把对象放在了某个全局变量里。只要保证等线程结束了才去取,就不需要把这个全局变量设为volatile的。
关于中断规则,我一下子想不出比较常见的用法,所以留给读者作为练习→_→。
这两招理论上能节省不少内存屏障。不过由于具体写代码的时候我们一般会使用线程池,所以这些规则并没有什么球用(╯‵□′)╯︵┻━┻。
锁定与volatile规则
锁和volatile的规则相对难理解一点,因为在实际程序中要看锁保护的状态和volatile的值才能推理两个操作之间的先后关系(因为有交叉执行,每次执行的时候先后关系可能都不一样)。
对了,由于acquire-release其实就是高层次一点的happens-before,所以下面的例子其实和acquire-release很像。
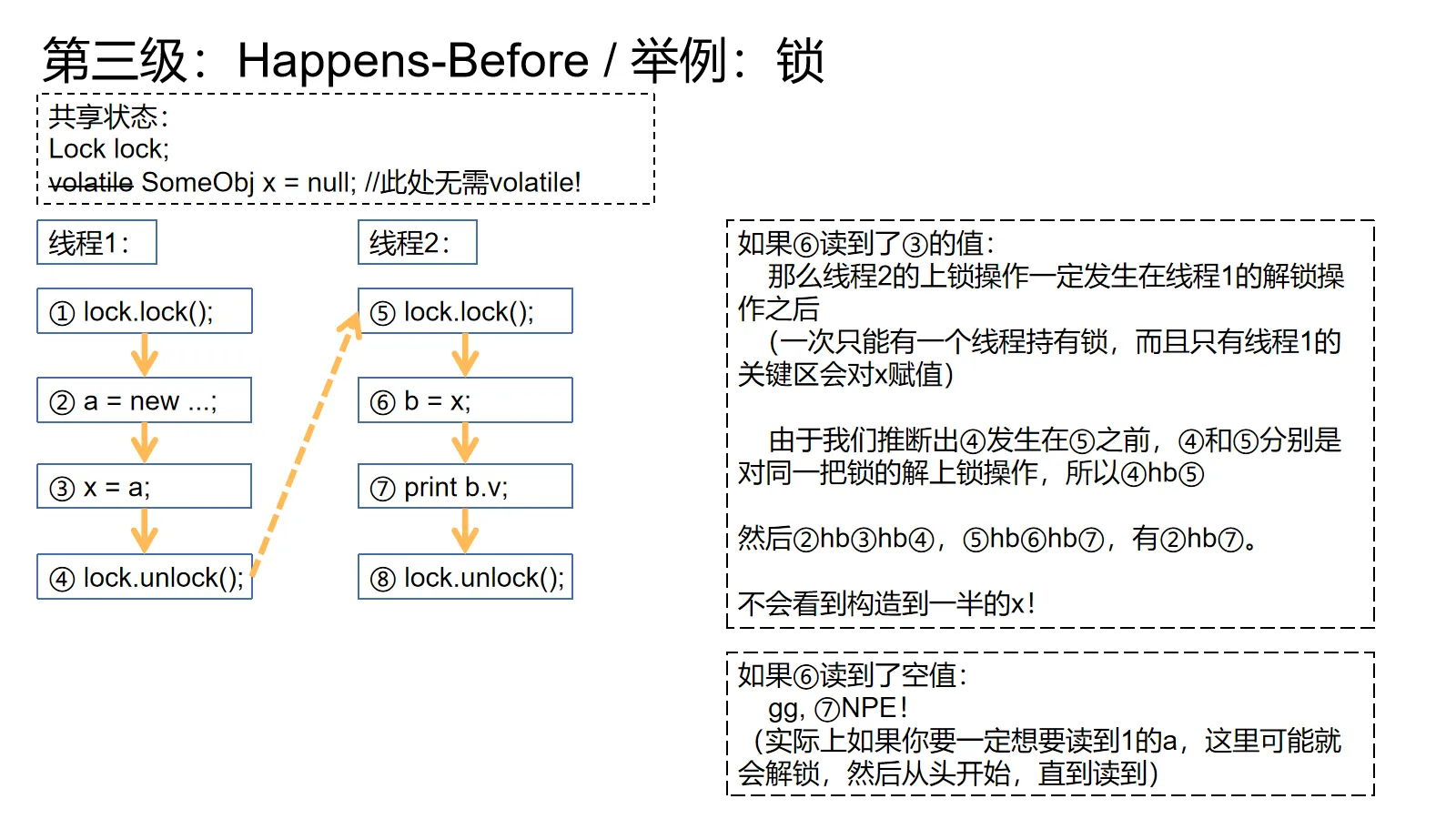
对锁而言,我们可以看上面的例子。在线程2的关键区内我们可以根据x的值来判断线程1的关键区是先于我们发生还是后于我们发生。要是x不是null,就是线程1的关键区已经执行了,先于我们。既然关键区先于我们,线程1的解锁操作肯定先于线程2的加锁操作,再加上同一把锁,所以线程1解锁hb线程2加锁。再加上程序顺序和传递性,线程1的new就hb了线程2的print,保证能读到构造完整的x
另外,如果x为null,那么线程1的关键区肯定还没发生,后于我们,那就没有关系可言了。
如果无论如何都想要线程1构造出来的对象,此处可以用一个信号来等待,或者解锁然后回到加锁操作前,等一会儿再进去,如此直到读到值为止。但是天哪,如果要传递对象,请务必考虑Future和并发队列。
还有,如果你觉得这玩意儿非常复杂,也属正常。实在不行就记住第一级的直觉:乖乖给读写上锁,就没有访存顺序问题!这里就是内存模型具体是如何保证这一点的。
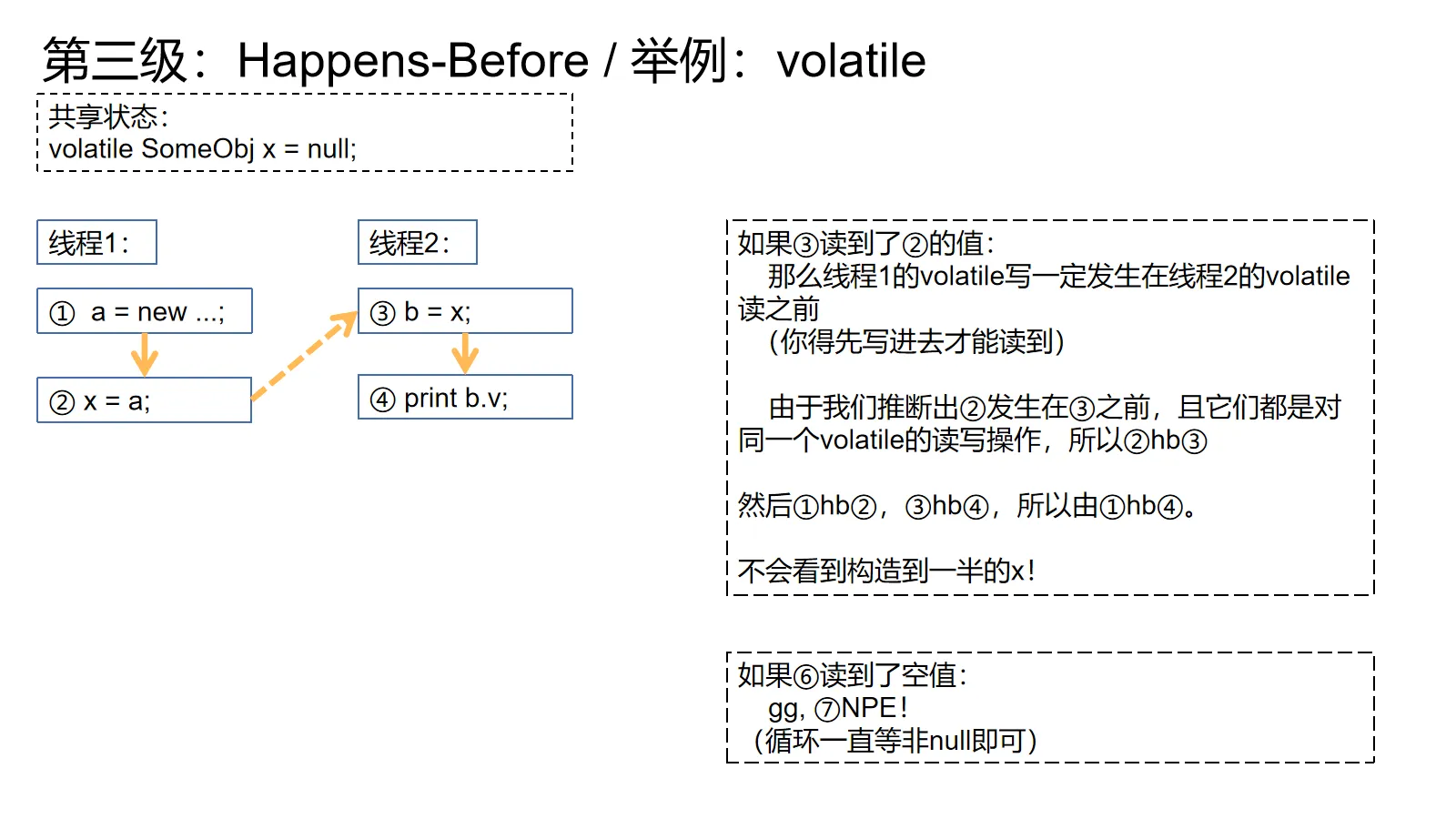
对volatile而言也是同理,我们要按读到的值来推导先后关系。进而建立hb,保证访存顺序。
对上图的例子来说,如果希望④一定会读到①的值,就让③不停地循环,直到读到非null值即可。
总结
这一部分的东西有一大堆,确实不好总结,但大致讲了这些东西:
计算机的内存模型是分层的,可以大致分为CPU ISA层和语言层,CPU作者负责实现ISA里的内存模型,语言虚拟机和编译器作者在ISA内存模型的基础上实现语言内存模型。
我们接下来用了三个模型,从易到难,从抽象到具体地介绍了使用语言内存模型的一些高层心智模型。
内存模型可以大致拆成两块:原子性保证和访存顺序保证。下面三个模型的原子性保证都是一样的:可以默认对64位及以下变量的赋值与读取是原子的。区别在于对访存顺序保证的描述粒度:
- SC-DRF,简单来说就是只要乖乖给共享状态读写加锁或者用现成的并发工具,就可以当访存顺序问题不存在。
- acquire-release,简单来说就是传递窗和并发队列。一个线程做了一些操作后,采用release发布自己的改动,别的线程用acquire读那个线程release出去的东西来保证可见性,进而避免访存顺序问题搞乱我们的程序。
- happens-before,真正写在规范里的语言内存模型。基本就算acquire-release的细化版,由八条规则组成。我们可以使用八条规则建立起一条跨线程的hb线路来保证可见性。
此外,我们还稍微介绍了一下内存模型的实现方式,以及举了一些例子来介绍这些模型,其中自然包括大名鼎鼎的DCL。
上面的例子基于Java内存模型,但是我认为按golang的规范和C++的解释来看,上面的模型应该也对其他语言(C#/Golang/C++等)适用。
后记:秀优越,感慨与追思
从资源的量来看,并发编程似乎是一个成熟到了内卷的领域。所有的Java自媒体,要么已经有了一篇多线程并发知识(主要是面试题)集锦,要么就是在攒一篇的路上(我如果算的话,那看来也不免俗啊)。但是量的增加也等同于质的拉跨——不少资料基本都是《Java并发实战》,《深入理解Java虚拟机》和《Java并发编程的艺术》的N手复制粘贴。
更糟糕的是,当中有些资料还是过时的,甚至是错的。我认为《深入理解Java虚拟机》里的内存模型是过时的。你如果去真的翻标准和JSR-133,你会发现JSR-133里根本没有工作内存和主内存的概念,规范必须翻到J2SE1.4才有书上写的工作内存-主内存模型。而这个模型从J2SE1.5开始就已经被JSR-133彻底砍掉重练,换成基于happens-before的模型了。诚然书中提到了JSR-133的修订,还对这个工作内存-主内存的模型做了一些修正。但是这并不是写在语言标准里的东西,即使你耗尽心力把这玩意儿和各种修正记住了,你所作出的推理的正确性还是间接的。这也是我想写这篇文章的动机之一。
手头的资料堆积成山,但是都不靠谱。面对这种现状,我认为破局之路就是依靠标准,依靠经典,依靠真正与并发问题日夜搏斗的人们。
从想要这么干到今日,大概已经有两年了吧。其间断断续续,试了两次,看了点东西,也有大把东西没看。时间长了就产生了自己会的幻觉,于是决定一抒愚见。若能给人些启发,那必是极好的。
感谢博文的作者,感谢会议上的讲者,感谢那些愿意为了降低这个领域准入门槛而牺牲个人时间的人。
如果有人希望深入学习,还请务必绕过我,沿着我的引用亲眼去看。
最后,也以此文简要缅怀@H-ZeX。我的同学与挚友,也是最有能力审阅本文的人之一。本文很长,但也只是我当年所说文章的影子。小生生活所迫,也只能先于此告一段落了。
文中疏漏松弛,还望海涵。
johnbanq
2021年5月