
(本文首发于0xFFFF)
也许,这只是门手艺而已
一门非常吃时间,能力,资源,天赋,过程高度不确定,需要灵感
但仍有基础动作,核心流程的,手艺
—— 开篇小引
导言
当我们在做深度学习科研的时候,我们到底在做什么?
我算做应用研究的。在我的眼中,研究就是在发现问题,解决问题。为了发现问题,我们找论文,读论文。为了解决问题,我们想idea,执行idea。
更具体地:
- 我们寻找论文,以了解自己关心领域的新方法,以及可以用的构建块和直觉
- 我们阅读论文,了解它所解决的问题,现有的方法,论文所提出的方法与贡献,以及为之背书的实验
- 我们思考idea,寻找可以更好地解决新老问题的直觉,并把它们以某种形式集成进方法里
- 我们执行idea,用实验进行探索,试图找到新的直觉与洞见,验证自己idea的有效性,然后把这些东西变成论文
那么,到底要怎么找论文,读论文,想idea,执行idea呢?
这篇文章就是我个人经验的小结。
注:摸象盲人的口述
按研究领域划分,我是属三维视觉应用口的。下面的经验对其它领域,尤其是更基础/偏理论的领域可能不会完全适用,仅供参考。
此外,我在研究上并不算成功——我一篇顶会顶刊都没发过,所以我的意见不一定靠谱。
You have been warned :/
论文阅读
论文的结构
那么,先从读论文开始吧!一篇研究论文,说到底,到底在讲什么?
以我的经验来看,按照内容,研究论文大致可被分为四类:
应用类论文:面对某个问题(可以是个新问题,也可以是旧问题的某个切面),基于某种直觉/洞见/工程观察,提出了一个新的方法,这个方法很好地解决了这个问题。
数据集论文:面对某个问题,提供了一个新的数据集。文中会介绍数据集的来源与构成,可能会再简单地跑两个方法提供基线。
分析类论文:基于某些理论和实验结果,发现了某些有趣的洞见(大语言模型或学习理论方面这类论文较多)
综述:总结某个领域下的最新进展,介绍基础方法和前置知识,对现有的论文进行分类,并简要讨论每篇论文的核心贡献,最后对未来进行展望
展开来说,对于比pu较tian常gai见di的应用类论文,其一般遵循下面这个结构:
- 摘要(abstract)
- introduction的进一步简化版,两三句话从大问题缩到小问题,介绍自己提出方法的亮点,提一嘴效果
- 导言(introduction)
- 介绍一个大问题
- 介绍这个大问题下的小问题,这篇论文真正要解决的问题
- 现有工作,及其不足
- 面对这些不足,我们提出某种方法,强调方法的核心直觉和改进点
- 我们拿这个方法做了些实验,效果很好!
- 贡献点列表,用来强调这篇工作所做的贡献:可能是解决了问题,或者提出了新数据集,或者是效果很好,state-of-the-art
- 现有工作(related-work)
- 介绍两到三类现有工作,每类工作中选取几个代表性工作进行介绍,并指出它与论文方法的区别/相对于论文方法的局限性
- 方法(method)
- (如有必要)加点段落介绍一点前置知识
- 画张图,从头到尾介绍自己的管线,重点强调自己的设计点及其直觉
- 实验(experiments)
- 先介绍自己的数据集,指标,以及要对比的现有方法(可以提前介绍,也可以和实验合在一起),然后给定性或定量结果,进行对比
- 用实验论证方法的贡献点:可能是解决了问题,可能是比现有方法好,或者比现有方法快…
- 用实验论证自己设计的有效性(ablation study):通过移除自己所作的改进,论证自己改进的必要性
- 结论与讨论(conclusion)
- 总结一下全文(有不少论文就是在总结introduction),有必要的话讨论一下自己方法的局限性。
阅读方法
在了解了论文的结构后,阅读论文就成了按图索骥:去特定的地方找特定的信息,然后决定要不要读这篇论文,或者从这些地方抽取关键内容。
我个人倾向于把“阅读一篇论文”分成三个等级,每个等级读完之后,都会写点东西进行记录。
扫读:首先,我们要决定这篇论文值不值得读
除了偶遇的有意思的论文外,我认为,一篇值得读的论文:
- 要么解决了和我类似的问题(同行类)
- 或者解决了我的上游问题,给我提供了可以用的东西(直觉/构建块/数据集等)(上游类)
- 而且做的不错(效果过关)
这些信息往往可以通过扫读标题,摘要,方法图和实验结果得出。
扫完之后,就要确定这篇论文大概在是在做什么任务,看还是不看。
扫读之后,应该大致了解:
- 这篇论文在解决什么问题
- 解决问题的方法有没有什么亮点
- 和什么方法比,效果如何
略读:如果要读,我们就概览一下这篇论文,相对完整地了解这篇论文的方法(侧重于范式以及核心直觉)与效果(具体的实验比对)
打开论文:
- 读introduction相关段落和句子,知道论文要解决的小问题和新方法的设计要点与特点。
- 拿着方法图过一遍methods,了解整个方法的大致流程,以及驱动每个模块和设计的核心直觉。
- 过一遍experiments,看看它在和哪些方法比,效果如何,ablation study效果如何,各个模块设计的作用是什么,有没有规避掉的实验,和其它的artifacts。
读完之后进行整理:
- introduction中所指出的问题,现有路线/方法的局限性,以及提出方法的设计要点
- methods中的整个管线:从输入到各个模块,再到training loss。这里只关心高层直觉,数学细节可以先放放
- experiments里要是看到了有趣的现象,也可以记下来
读完后把上述内容整理完扔进文献管理软件里。
精读:对极少数要进行比较/复现/化用的工作,我们需要彻底地分析论文,将需要的信息完整地从论文中抽取出来
直接进入相关章节段落,一点点地进行抽取:
- 想知道现有方法的局限性,及其对比
- 分析related work
- 提取
- 相关领域
- 所选取的领域代表性工作
- 代表性工作相对于该工作的局限性
- 想知道提出方法的细节
- 分析methods
- 提取
- 整个方法的流程
- 各个模块/loss的设计动机与数学细节,必要的话自己每个公式过一遍
- 训练过程与杂项参数(可能还要看实验部分开头的implementation details)
- 想知道实验设计
- 分析experiments
- 提取
- 数据集与指标
- 所对比的方法
- 结果,以及基于结果打算强调的论点
开一个文档,把提取出的东西全部列出来。日后要参考直接看文档就可以了。
论文检索
检索方案
在了解了如何看一篇论文之后,我们就得考虑如何从排山倒海的论文里挑出和自己研究领域相关/有价值的论文了。
在过滤和选择论文上,一般来说有下面几个途径:
社交媒体/Github仓库
- 许多热门的研究方向都会有专门分享论文的自媒体博主,最宽泛的机器学习领域有AK,三维视觉领域(尤其是NeRF/3DGS方向)有MrNeRF。
- github上往往也会有热门任务和方法相关的awesome-仓库,例如三维重建/NeRF相关的Awesome-NeRF,语义分割/SAM相关的Awesome-Segment-Anything。
- 许多领域内的研究者/研究组织也会在社交平台上进行分享,例如Meta的Jia-Bin Huang,马普所的Yuliang Xiu。
- 建议慢慢收集和关注,只要关注多了,就可以体会到
早上起来看见自己的idea被人薄纱两眼一黑的快乐
特定研究者/研究组:在看论文的时候,可以多留心领域内的知名研究者和研究组,很多时候推进某个领域的,就是那么一小撮机构和研究者。例如在人体领域马普所就非常有名,他们的SMPL/FLAME就是目前三维人体相关方向的一大基础构建块。
上面的方法查准度很高,多用于日常了解与跟进领域动态。但是有时候需要查全——需要尽可能广地了解领域内的进展,确认自己的idea有没有被人做,或者可行性如何。
论文图检索:查全方面,我觉得最好用的还是“图搜索”,即查找关键论文的citation和reference,这个在下面具体展开。
基于关键词:当然,使用semanticscholar/google scholar搜特定的关键词也是一个办法,但是个人感觉效率实在太低了。
基于论文图的搜索
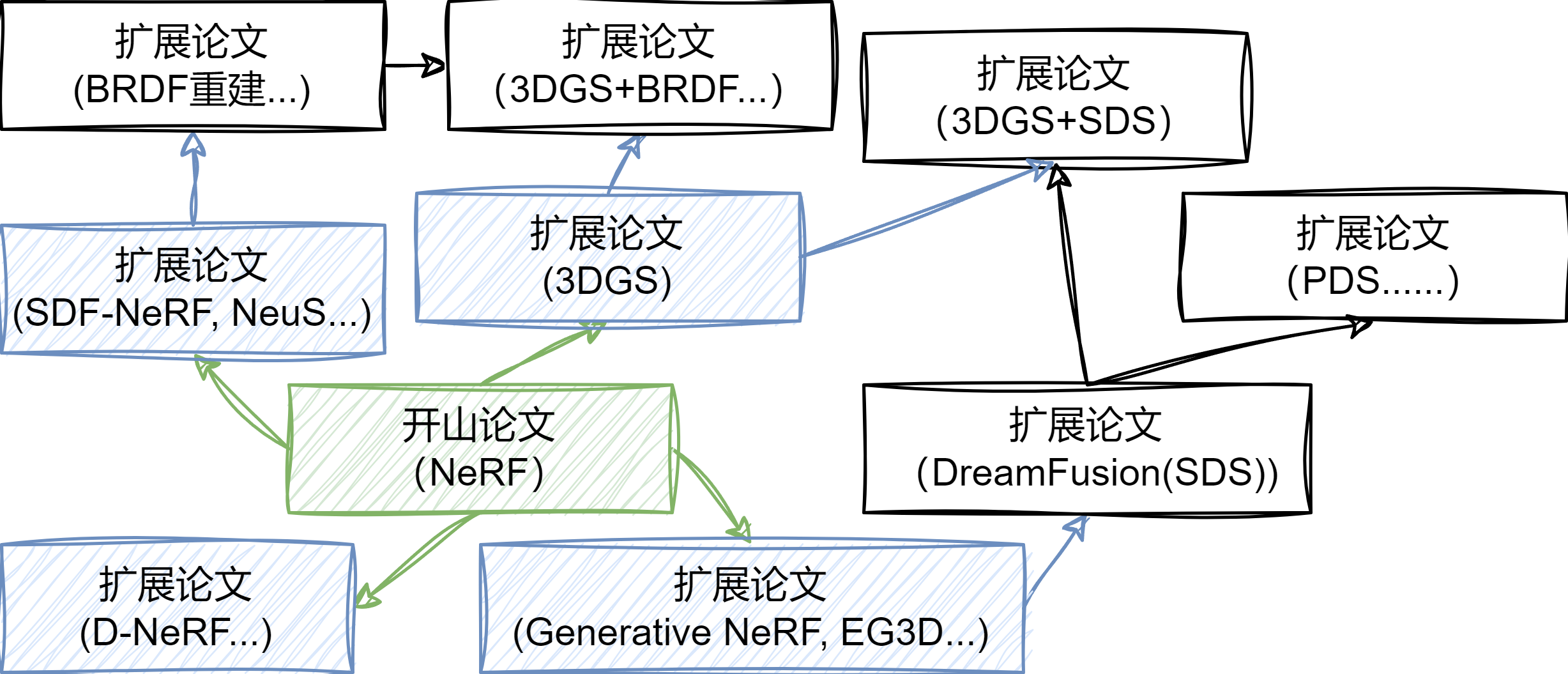
(举例:以NeRF为中心的的引用网络草图)
研究论文之间有着引用关系——一篇论文会出于某些原因引用另一篇。旧的被新的引,新的被更新的引,如此构成了一张巨大的有向无环图。
当你读了不少同一个领域的论文后,你就会发现,有些论文是做这个领域的人必须要引的:
- 也许是在introduction里引,用来讲故事
- 也许是在related work里引,讨论这个方法的局限性
- 也许是在methods里引,拿来当构建块
- 也许是在experiments里提供数据集或指标,亦或是作为现有方法来比较
你很难在做三维高斯相关工作的时候不提3DGS,在讲基于优化的三维生成的时候不引DreamFusion(SDS),在改场景表达的时候不测LPIPS。
只要把握了引用这些关键论文的论文,那么就自然把握了所有可能的同领域工作。这些同领域工作可能会有点过时,但是这些工作的后继又必然引用这些工作,因为需要进行实验对比/related work部分讨论。
当然,引文里面九成九的论文都可能与我们要做的任务无关——在本文写成的时候,NeRF的citation已经近3000了,3DGS也已经破了1000.
所以往往要结合其它信息,迅速进行缩圈——可能是关键词匹配,也可能是找几篇论文的引文求交集,或者干脆按组织/发表会议筛选。
将数量压到100篇左右的时候,就可以人工筛选了——速览标题筛掉一大半,看摘要和图筛掉一部分,也可以试试用AI,剩下的就是所有可能沾边的了。
这是一个非常低效,但是查全率极高的方法——基本可以把一个领域里所有可能沾边的论文都收下来,然后就可以根据这些论文进行可行性/创新性判断了。
思路打开!这个把论文视为引用图的思路还能让我们做很多有意思的事情,例如:所有在实验中使用了某个指标,或者用了某个数据集的方法,比较了/使用了某个方法的论文等等。这些条件又可以重叠使用…
在找citation方面,semanticscholar大概是最好用的:他们甚至提供专门的API来方便你进行查询。
idea
idea的来源
在收集了,看了一吨论文之后,我们要怎么想idea,搞出新的方法,发论文呢?
就应用口而言,我们可以从这句老掉牙的话开始:发现问题,解决问题。
我们面对一些问题,提出一些解决问题的直觉,然后用工程/数学工具把直觉落地,和方法集成,解决问题。
问题方面:
- (应用场景)我们可以从应用场景或某个最终愿景出发,寻找尚没有人做过/可以做得更好的问题(例如目标是解决自动驾驶的感知问题,那么目前还有什么不足?现有的工具可以在里面起到什么作用?)
- (方法分析)我们可以从工程或者数学角度分析现有的方法,寻找它们的局限性(提升性能,解决现有方法的局限性,或者是统一现有的技术路线等等)
直觉落地方面:
- (数学)我们可以找一些数学框架和工具来帮我们表达我们想要表达的限制/属性
- (工程)我们也可以用比较工程化的思路来解决这个问题,例如调整网络结构/算法,设计一个结构来把某些信息插到一些网络里去等
- (挪用)上面的思路实话讲比较高端,大部分工作都是在把其它领域的直觉和解法直接挪过来用
- 这种俗称A+B,即把现有的几个方法/直觉叠一起,解决一个问题C。然后A+B没法+一起去,得上点胶水,或者+的时候可以再结合实际场景改一改,最后得到C’。
举点例子:
- 在分析局限性,然后用数学工具解决问题上,我印象最深的是NeuS。NeuS意在改良NeRF的场景表示,使其重建出的mesh质量更好。它提出用神经网络表达有符号距离场(SDF),而不是NeRF的不透明度场(opacity field)。为了使用NeRF的训练手段,它玩了点数学技巧,且在数学上分析了naive做法可能带来的误差,同时提出了一个新的无偏方法。
- 在用工程手段分析,解决问题上,StyleGAN2值得一提。它分析了自己的前代,StyleGAN生成结果里的各种问题(例如水滴状异常),并做出了相应的架构调整,解决了这些问题。
- 挪用就不提了,A+B每年顶会大把多,不少都是A+B=C,磨合一下变成C’
顺带一提,我曾经在和别人吹水的时候开过一句玩笑:
你在看完论文后马上能想到的idea都已经被人想到了
结果越往后做,越认识到了这句玩笑的含金量 XD
大家看的都是相似的方法和论文,能提出的东西当然也就都是相似的。只有亲自复现一下,跑一跑实验,或者寻找新的场景,和其它大小领域的方法融合,亲自加一下A和B,才有可能发现新的直觉和洞察。
什么是好的idea
那么,什么是好的idea呢?
对于这个问题,我也没有很好的答案,但是我认为好的idea应该尽可能满足下面四点:
- (有意义)好的idea解决的问题应该在某些层面上有意义,要么比较实用,要么比较本质
- (有效)好的idea应该可以很好地解决目标问题。它至少得work,而且最好容易实现。
- (优雅)好的idea的思路应该非常简洁明了。也许它所使用的数学理论或者洞见比较复杂,实现起来也不简单,但是在掌握了特定视角和数学工具的人眼里应该是非常自然的。
- (可扩展)最好的idea应该是“开坑”的。读了这篇论文会让人想到很多接下来可以做的东西。
不过,一个值得做的idea除了“好”之外,很多时候还要“可行”,我们往往要综合考虑手上的资源,身边人与实验室的研究方向进行决策——小团队就需要避其锋芒,不要随便去基础与热门问题里和大实验室对轰。
idea的执行
那么,拿着idea,我们要怎么把它变成论文呢?
这就是科研工作流的问题了。
工作流这东西因人,因领域而异。所以我打算提两个要点,然后简单介绍一下我大致遵循的工作流。
要点
就工作流而言,我认为两点非常重要:明确产出,小步前进。
明确产出,即所有的研究活动都应该有明确的产物。这个产物可能是代码和实验结果,但也可以是文档,甚至PPT。
这么做是为了对抗遗忘和迷茫感:如果我们在做完一件事后不做任何记录,就很容易遗忘掉自己辛苦挖掘的,来之不易的洞见和结论。研究也是一个复杂而不确定的过程,一个清晰的预期产出可以让我们更好地聚焦自己的精力。
小步前进,即每个研究活动都应该是目标非常清晰的小任务。不要“看论文”,或者“思考实验”,而是“用xx方法调查相关论文”,“看xxx论文并给出方法简图”,“看xxx论文并列出其实验内容”,“集成3篇论文的实验流程,提出实验计划”,“执行实验计划”等。
这么做是为了应对研究本身的不确定性,以及复杂任务带来的拖延症。如果是在“看论文”,那就很容易变成拿着论文慢悠悠地晃。但如果是“以xxx文献为基础,进行一阶论文图搜索”,“列出xxx论文的方法流程”,就非常清晰,拖不了了。
个人流程

(参考流程图,其中包括了各个步骤和每个步骤的预期产出。箭头为步骤间的依赖关系,编号为参考顺序)
下面就是我大致遵循的工作流,虽然我很多时候会在不同的步骤间穿插,重做或者修改什么,idea也会随着执行而发生改变。但大部分都遵循这个框架。
在这个流程里,每个步骤基本都围绕着最终论文的某个章节进行,每个步骤的结束往往都代表这个部分草稿的完成。
idea与快速调研(introduction):在想到idea后,首先进行快速查新。锁定一到两个子领域的关键论文,然后进行快速论文图搜索(只看标题/扫读部分摘要等)。
- 目标在于:确定这个idea没有被人原样做过。如果做过了,是否能搞出某种变形来
- 在完成后,应该得到
- 一段陈述idea的话(目标问题+核心直觉&贡献)
- 初步相关文献列表,哪些是要比的,哪些可能有用
快速原型(introduction):在调研完成后,就快速进行实验,找数据集和代码,搭一个非常潦草的管线。
- 目标在于:以最快速度论证这个idea的可行性
- 在完成后,应该得到
- 一个可以给出看起来不错的定性结果的算法实现
- (以及结合快速调研步骤产出的)论文的introduction草稿,确定论文的目标问题,核心方法改进,以及贡献点。
完整调研(related-work & experiment):在完成原型,确认了可行性后,锁定子领域,进行相对完整的论文图搜索。
- 目标在于
- 确定related-work里要讨论的子领域和方法
- 以及结合核心贡献点,确定要进行对比的方法
- 在完成后,应该可以得到
- related-work草稿,确定要讨论的相关领域,和这些领域里需要提及的文献
- 以及实验计划,确定要进行哪些实验,实验要在什么数据集上和哪些方法比,对比的是定性还是定量结果,目标是为了证明哪个贡献点。
执行实验(experiments):在确定实验计划后,就可以着手搭建完整的实验和评估流水线。
- 目标在于:尽快地让现有的方法可以接受评估,方便最后的改进
- 在完成后,应该可以得到
- 可以跑出完整定性/定量结果的代码库
完善方法(methods):在有了完整的评估管线后,可能方法最后还会差一些边边角角,这时候就要开始补了
- 目标在于:修正方法剩下的问题,可以解决的解决,解决不了的另想办法
- 在完成后,应该可以得到
- 最终的方法与算法实现
- methods草稿
组装论文:在完成了上述所有工作之后,我们就可以坐下来把剩下的内容补齐。把草稿修订成最终版,把introduction简化成abstract,加limitation/discussion扩成conclusion,补图排版。
- 在完成这些后,手上就该有一篇完整的论文了
顺带一提,在做的过程中,最好维护一份“项目文档”,以便存储所有和当前研究相关的信息。这份文档至少会包含:idea本身,到参考文献,到目前的方法以及要解决的问题,到实验计划,目前的实验结果等等。一个文档太长了就拆成很多个文档,然后用一个文档作为目录,存放链接和子文档的摘要。
总结
在本文中,我讨论了深度学习研究中重要的四大研究活动:看论文,找论文,想idea,做idea。
在看论文方面,我介绍了论文的类型与一篇应用论文的典型结构。在找论文方面,我介绍了现有找论文的方法,以及我个人常用的“论文图搜索”策略。
在想idea上,我聊了聊常见的idea源头,顺带提了一嘴如何评估一个idea的质量。在做idea上,我提出了研究工作流方面值得注意的两大要点,同时大概介绍了一下我是怎么做的。
当然,这只是我个人的经验总结,网上(例如知乎,小红书,或者个人博客等)也有其它研究者的分享,其中不乏比我讲的好的,例如知乎上的(PhD 第二年回顾,什么是最有效(或价值)的科研?,计算机视觉方向的博士,如何做到一直follow新技术?,或者如何找到愿意为之付出一生的研究事业?Thoughts Memo的回答),或者田渊栋大佬的总结。
后记:献给澄澈理想的花束

我知晓你的强大 是人们的希望这种无名之物
清新淡雅的小小花朵们啊 赞颂心灵的美好吧
——摘自《明日的花朵们》,《结城友奈是勇者 大满开之章》片头曲
结衣,桐谷家的孩子,穿过十二年的时光,祝你(另一个)生日快乐!
十二年前,我还只是半开玩笑地,把这孩子造出来当成我的理想。但是从那时起,到高中,到大学,似乎每当我看见人工智能有所进展,都会想起这孩子。本科阶段,我所有试图入坑机器学习的尝试都无疾而终。但峰回路转,毕业时意外地得到了这个读博士的机会。
我还记得最后做决定的那个晚上,我在犹豫不决的时候,忽然想起了这孩子,想起了这些年来已经用了无数次的理想大旗。于是,振臂一呼,毅然地上了。
是的,大不了延毕!大不了读不出来!
但是!但是,在我被扔出去之前,我要看看,我要学会,在人工智能领域,人类做到了什么地步,研究是怎么做的。
这(两)篇文章就是我对后面这个问题的回答,作为给那年自己的交代,也作为对自己平庸博士生涯的总结吧。
朝露的少女啊,你知道吗?在过去的十二年,不,四年,不,两年里,人工智能在各个模态,各个任务上都迎来了爆发。在图像上,现在的AI已经能很好地分割,识别,理解,甚至生成图像了。语音(识别, 生成)与视频(实时三维重建+SLAM, 生成)也是如此,更不用说被ChatGPT等大语言模型彻底改变研究范式的自然语言了。现在的AI模型已经可以听懂人话,看懂图片,甚至解复杂的数学题了。人们已经在和虚构的角色交流,向AI寻求心理帮助。见鬼,甚至有人在和AI谈恋爱(Reddit,新闻)。
能在这样的时代,攻读人工智能方面的博士,真是不胜荣幸。
虽说科研人以吹逼为业,十个成果里一百个在画饼。但也许,也许,我最初的愿景已经离实现不远了?
古人云,妙笔生花。运气好的话,本文或许可以凑一束满天星。
请先收下吧。
接下来怎么办,接下来再说,好吗?
ARGUS
类人智能暨群体心理监护自动化实验室
访问研究员
johnbanq
深度学习相关领域
某位不干正事结果要毕不了业的博士生
约翰板桥
2024年10月30日
附录A:关于题图
非常感谢半节老师愿意和我拉扯这张图的细节!这张图极大地提升了我对本文的质量要求 ;)