
(本文首发于0xFFFF)
深度学习不是一门纯理论学科
—— 开篇小引
导言
深度学习不是一门纯理论学科。
这点在模型规模逐渐增加,逐步实用化的今天尤其明显。我们需要处理上G甚至上T的数据,然后用多张显卡,甚至在多台机器上,用数天甚至数月的时间训练一个模型。越来越多的研究成果不是基于数学直觉驱动的,而是基于工程实践发现的。
这一趋势,加上机器学习本身的特点,把写/调试深度学习代码变成了一件令人头疼的事情:模型规模和训练时间抬高了代码出bug的代价,机器学习模型也有着一定程度的适应性:有时候就算代码在处理上有些问题,神经网络也会试图在训练中进行补偿,最终得到一个性能不理想的模型。让人分不清模型效果不理想,到底是因为代码有问题,还是模型设计的有问题。
为了应对这样的工程挑战,我们必须学会如何系统性地进行思考,学会如何有组织地分析一个深度学习系统与代码库。
心智模型就是用来干这件事情的:通过尽可能完备地描述一样东西的组成部分与各个切面,我们就可以有的放矢地提问,快速地进行排除和聚焦,弄清楚哪里可以改进,问题可能会出在哪里。
本文的目标之一就是介绍我所总结出的,关于深度学习系统与代码库的心智模型。
更具体地,我将在本文中:
- 分享我对深度学习系统与代码库的心智模型。讨论它们的结构,以及围绕这些模型组织起来的,我经常问的问题。
- 提一些实际工程要解决的一些琐碎的问题,以及我个人用过且觉得好使的工具。
- 讨论一些具体工程实践上值得一提的,值得去达成的要点。
让我们开始吧!
心智模型:机器学习系统
本质
让我们从头开始:深度学习是机器学习的一个分支,这个分支专注于研究深度神经网络,并用它来解决机器学习领域的问题。
那么机器学习到底在解决什么问题呢?
我认为:绝大多数深度学习乃至机器学习模型的目标,都是学习一个函数,一台把A变成B的机器。
这方面,传统一点的例子有手写识别(手写图片->数字),图片分类(图片->类别),物体检测(图片->一个或多个圈住指定类别物体的方框)。
而最近那些大热的AI模型也是如此:ChatGPT等大语言模型的本质是经过RLHF微调的GPT,GPT是一个预训练模型,它在预训练的时候学习的是句子补全(一段文字->下一个单词)。AI画图要复杂一些,它学习的是对“所有会被人类认识成画作的图像”这一集合的采样函数(随机数->一副画),然后文生图就是想办法给这个集合加一个“满足文本描述”的限制而已。
万变不离其中,本质上都是在学习映射关系,f(x)=y。
引子
但是这个函数可能非常复杂,我们没法直接用代码写出来。
所以,我们定义一个带着参数的“泛用函数” f(theta, x) = y。这个“泛用函数”可能表达一类函数,具体是哪个函数取决于参数(theta)是多少。
只要保证这个“泛用函数”足够泛用,包含了我们想要的函数,问题就从找函数,变成了找这个“泛用函数”的参数。
那么如何找这个参数呢?
我们决定让模型从例子中学习。我们收集一些例子,然后设计一个量化指标。我们希望找到一个参数,这个参数代表的函数在量化指标上尽可能优(误差最低,或正确率最高)。
我们使用随机梯度下降(SGD)算法来找这个最优(或尽可能优的)参数。它会基于反向传播算法,从量化指标,计算参数的梯度,然后基于梯度更新参数。
此外,我们可能对模型也有一些其它方面的期待,或者希望这个优化过程不会产生奇怪的结果。所以我们会再追加一些量化指标,来让优化过程更加平稳。
心智模型
好了,让我们用术语把上面的东西再讲一遍吧
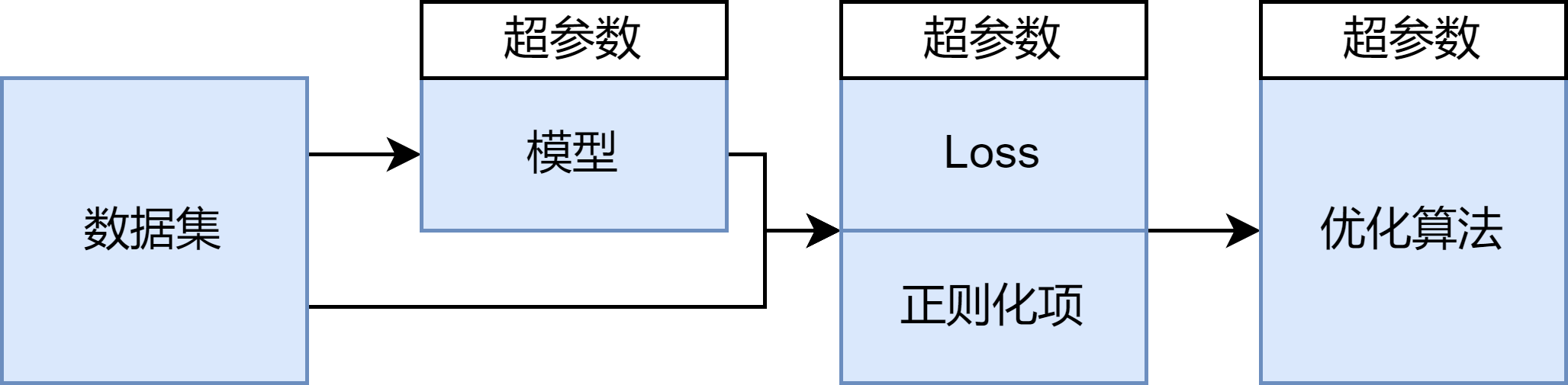
“泛用函数” -> 模型架构(Transformer/CNN/…)
“泛用函数的参数” -> 模型参数
”例子” -> 数据集
”量化指标” -> Loss
”让过程更加平稳的指标“ -> 正则化项
“SGD算法” -> 反向传播与优化器
此外,由于梯度一般只会从一个最终的标量值反推,Loss和正则化项一般会被加权求和成一个最终值。
这些loss的权重,一些决定模型内部结构的配置(层数等等),以及优化算法的学习率被统称为超参数,它们不会被优化算法调整。
我们设计模型架构,构造数据集,设定超参数,初始化模型参数,然后在正则化项和Loss加权和的“带领”下,用基于SGD的优化器进行优化,迭代模型的参数:
一个模型架构代表一类函数,其中每种参数代表一个具体的函数,这就组成了一个“参数空间”。优化的过程就是从初始参数开始,不断地向着loss梯度最低的地方“行走”的过程:

(对所有可能的模型参数,数据集+loss对它们进行了打分,分数可以视为“高度图”
我们从高度图的某个地方出发(1.初始化),一步步地沿梯度所指的方向走(2.逐步行走),最后到达某个较优结果(3.优化结束),图自slideshare上的Introduction to Machine Learning)
注:但是强化学习/对抗学习/Diffusion/大规模训练…
这里所讲的只是最基础的监督学习流程,实际上现代生成式AI/其它模型的训练要更复杂些,例如基于Generator/Discriminator的对抗学习,基于action/state/reward的强化学习等等等等…
而且,为了实现多机多卡大规模训练,实现起来也有一大堆乱七八糟的算法(虽然很多时候用起来就是设置一个框架的参数而已)
这里篇幅所限,就只讲最基础的版本了,相信基于这个基础版本的剖析对其他学习流程也有用。
基于模型的分析
是的,这是所有搞深度学习的人都知道的基础知识。但是只有把它明确地摆出来,我们才能系统性地进行分析与思考:
- 数据集
- (格式)数据集的内容与格式是什么?
- (来源与分布特点)是如何采集的?有什么特点?有多少空值和错误值?如何处理?会造成什么影响?
- (预处理)进行了什么预处理?什么时候进行的?
- 模型架构
- (格式)模型是否对输入数据的格式与分布有假设?数据集符合假设吗?
- (设计)模型的架构是哪来的?每个模块和连接是怎么推出来的?基于什么直觉或实验结果?是否满足当前任务?
- (超参数)模型的超参数是怎么设定的?各个超参数的影响是什么?
- 若要使用预训练模型,还要考虑:
- (架构接入)预训练模型和模型剩下的部分如何连接?
- (数据差异)模型的预训练数据长什么样?和现有的输入有多大差距?Loss与训练过程如何?
- Loss与正则化项
- (设计)Loss与正则化项是在试图编码什么直觉?有什么样的数学特性?
- (数据/模型-Loss耦合)Loss是否对输入数据的格式/模型输出有假设?是否符合?
- (超参数)各个Loss和正则化项的输出值域范围是什么?需要赋多少权才能让它们的影响相接近?应该重视哪些项,不重视哪些项?
- 优化算法
- (优化算法)打算使用对抗训练?强化学习?还是其它特殊优化方式?
- (优化器)一般都是使用Adam,不会有大变动
- (超参数)学习率是否过大导致模型难以收敛?是否过小使得收敛太慢?batch_size是否过大导致计算过慢?太小导致梯度质量差?
- 优化过程
- (Loss)各个Loss与正则化项的值开始与结束是多少?中间演化的趋势是什么?
- (梯度)训练过程中模型各模块的梯度质量如何,能很好地把模型引向好的地方吗?有无过大/过小/nan梯度?梯度统计分布如何?
- (可视化与评估)模型在训练中看到的数据/推理中间的结果/输出的结果长什么样?
- (泛化性)模型在训练集和验证集上的定性结果和定量指标如何?是否发生了过拟合?
蒙着眼睛瞎猜瞎试,往往只会事倍功半。系统而有组织地提问和思考才是排除问题,寻找解法和工具的关键(虽然有时候还真需要直觉)。
心智模型:机器学习代码库
心智模型
上面所提及的,只是机器学习最核心的训练过程,一个完整的代码库当然还包含其他东西:
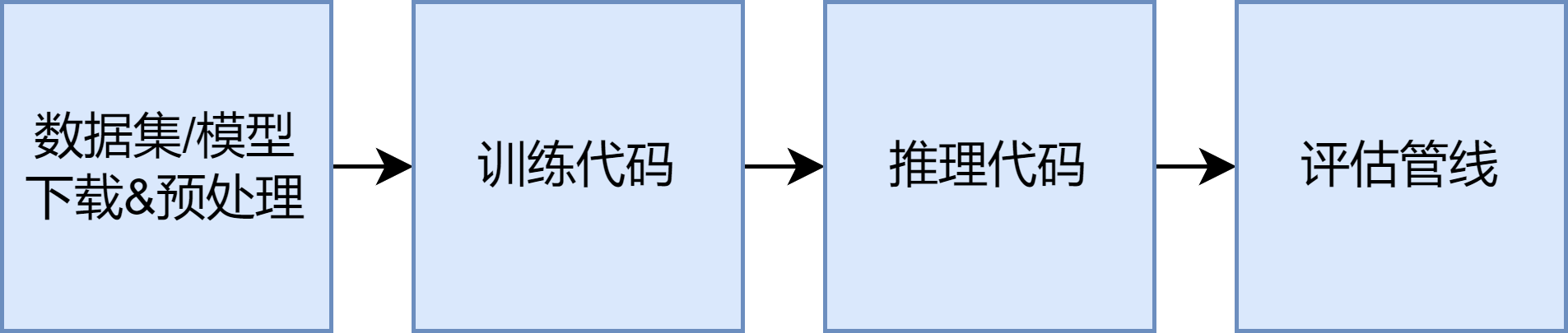
拿着一个没有现成模型的代码库,从头开始的流程一般是:准备数据集和要用到的现成模型,跑训练代码来训练我们的模型,训练完了看看日志,拿着模型和推理样例跑一下推理demo看看效果,然后用评估管线做系统性的定性/定量分析。
基于模型的分析
- 数据集/模型下载与预处理
- 我们要怎么下载训练数据集和推理样例?要以什么格式放到哪里?
- (如果用了的话)我们需要哪些已经训练好的现成模型?要以什么格式放到哪里?
- 训练代码
- 就是上面机器学习系统的代码实现。要怎么跑起来?超参数,数据集如何指定?什么格式?日志和训练好的模型会输出到哪里?
- 推理代码
- 拿着已经训练好的模型,我们要怎么跑推理?模型,数据样例要如何指定?什么格式?
- 评估管线
- 如何运行论文中描述的定性/定量评估?我们要用什么数据集(源头与格式),和什么评价指标(指标本身可能就是个神经网络,所以也要考虑它的训练集和输入输出特征)?
一个完整的机器学习代码库一般都要包含这些东西(虽然放出来的有时候可能只有推理和训练,甚至只有推理)。
关于复现代码库/论文
拿着别人的代码库/论文,复现的顺序一般是:配置依赖环境->准备数据集/预训练模型->推理与定性评估->定量评估->训练。
重点在于先建立标尺,没有标尺我们就没法明确地知道自己复现的结果到底是好是坏。
如果不提供推理代码/已经训练好的模型,自然就要把训练提到评估的前面(但是如果一个工作连推理代码/模型都不给,那可能复现起来就会有很多暗坑)。
余下的工程细节
心智模型
但还没完事!别忘了那些琐碎的工程细节:
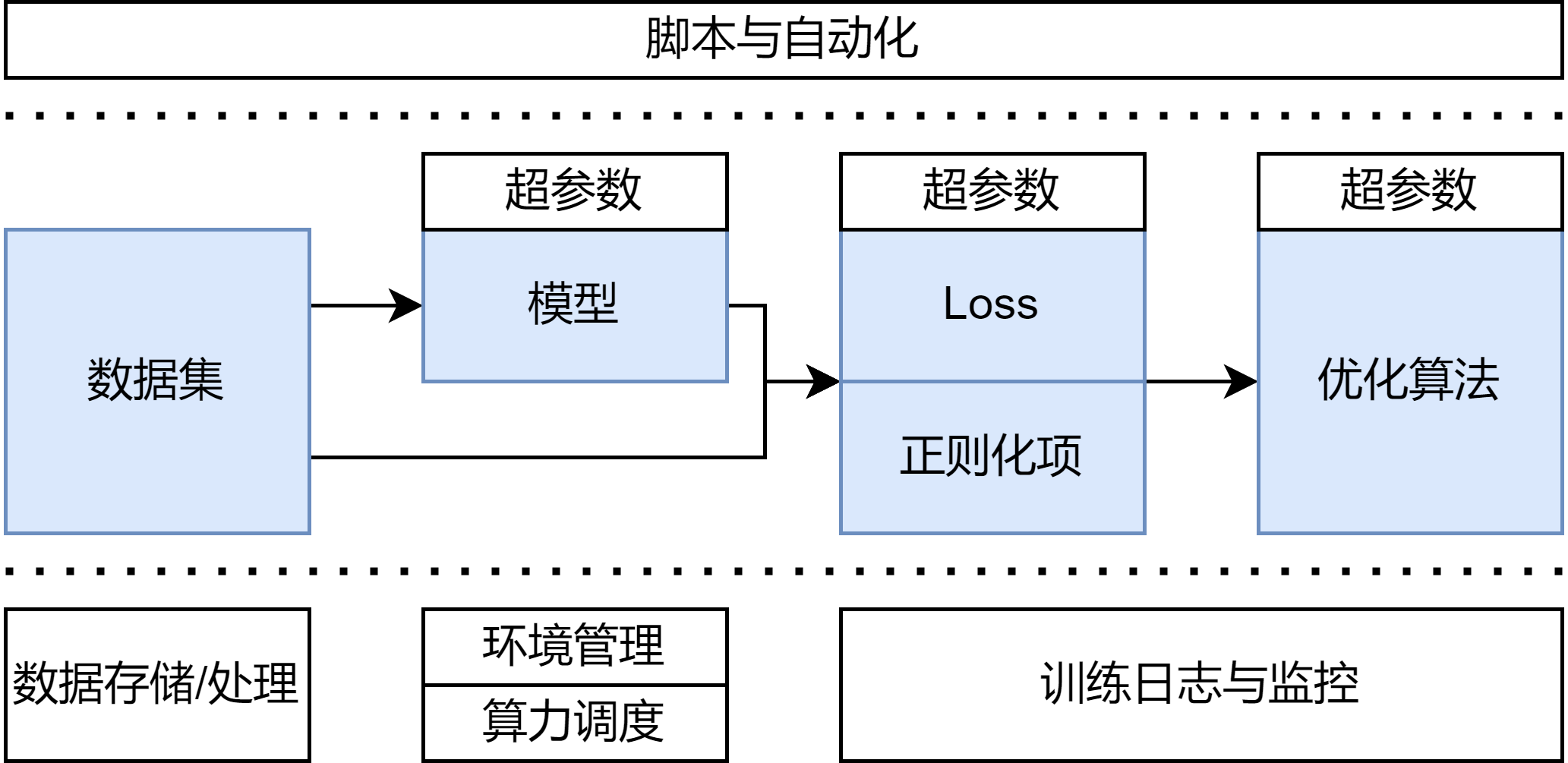
基于模型的分析
- 数据存储与处理
- (存储)我们的数据要放在哪里?怎么下到本地?
- (预处理)是否需要预处理和增广?这些操作是在线进行还是预先进行?
- 算力调度
- (云服务)我们要去哪里租借算力?
- (自建管理)如果手上有共用集群的话,要怎么做算力的调配与管理?
- 环境管理
- (python依赖)我们要怎么准备正确版本的python和其它pip包?
- (原生依赖)怎么准备cuda等原生依赖?
- 实验日志与监控
- (监控)训练往往需要在多台机器上运行很久,我们要怎么收集训练日志和各项loss指标?挂了/跑完了要怎么通知?
- (归档对比)如何把训练过程与产生的模型进行归档,方便分析对比?
- (超参调优)如何进行超参数调优?
- 推理与可视化
- (推理)我们要如何提供推理demo?
- (可视化)为了方便检查数据集/模型/推理结果,我们是否需要准备额外的工具?
- 脚本与自动化
- 我们能不能把上面这些琐碎而无关紧要的流程用脚本全部自动化?
这些工程细节(尤其是配环境),往往才是日常工作中最恶心的问题。
一般来说,对于这些问题,每个人都会有自己偏好使用的工具。
限于篇幅,我个人偏好的技术栈请见附录。
值得考虑的工程要点
除了枚举技术细节之外,我还想追加三个值得一提的要点:
可审计性:代码和数据应该是可审计的,我们应该可以很容易地知道代码接受过哪些改动/数据集接受过怎样的处理,及其理由。
可审计的代码历史可以让我们非常方便地比较两个实验的架构差异。知道了数据的处理过程,就可以让我们很容易地比较和改进预处理管线,以及知道它和现实采集的数据有什么不同。
代码方面,最直接的做法就是充分地使用git,同时严格遵循小而原子化的commit。只要做到这点,加上在训练前保证没有没commit的改动,再记录好每次训练的启动命令,就可以根据训练的commit进行非常全面的架构比对,分析每个架构改动。如果还保证了训练的可复现性(手动初始化随机数/强制并发操作顺序等),我们甚至可以拿着commit和命令行完整地复现一遍训练。
数据方面,这个问题其实叫数据血缘(Data Lineage)。对小规模数据可以暴力破解:在代码库里保存预处理脚本,在数据集文件夹里开个文件,说明数据集来源,预处理流程与数据格式,然后罚神赌咒再也不改。大规模数据可能就需要数据版本管理和处理管线管理工具了,例如DVC和dagster。
反馈速度:实验应当尽可能地快,尽可能地自动化。
试验越快,出结果的速度就会越快,我们也就可以更快地迭代方法。试验应当尽可能自动化,这样就能避免经常干预造成的时间碎片化,进而保持心流状态,让我们可以做一些更困难的事情。
不要忽视那些偶尔的手动干预所造成的打断!一个小时能做的事情远多于两个三十分钟,远远多于四个十五分钟。
在加快速度方面,可以考虑缩短训练步数,缩小数据集规模,甚至缩小模型。这在debug的时候尤其重要——要是一个debug试验要跑上小时,那么可能跑完了人都已经忘了在查什么问题了。
自动化方面,就要记得挽起袖子多写点自动化脚本了。
可视化:我们应该有工具可以轻松地观察训练所用的数据集,模型的中间结果与最终的输出。
毕竟,直接观察很多时候比拿着间接指标瞎猜管用。
实践起来就是记得在tensorboard里多输出中间结果,同时在需要额外工具的时候舍得花时间写一些GUI工具。
总结
在本文中,我们讨论了深度学习研究中的一些工程实践。我们了解了机器学习系统与机器学习代码库的心智模型,并围绕它们列举了一系列日常分析用的常用问题。此外,还提了一嘴剩下的工程细节,以及值得考虑的工程要点。
如果想系统地学习深度学习工程相关的知识,可以看看MadeWithML与Full Stack Deep Learning。
顺带一提,深度学习系统是一种软件系统,所以软件领域的一些思想和方法论也值得参考,尤其是极限编程相关的方法论。因为深度学习系统的开发往往是迭代式的,而且目前的应用口研究节奏快,变化多。
后记:赠与机械灵魂的挽歌

伊甸成为了永恒的摇篮,孕育着机械之中诞生的纯洁灵魂。
—— 摘自视觉小说《亚托莉 - 我挚爱的时光》
开宗明义,谨以本文纪念《亚托莉 - 我挚爱的时光》动画完结。
四年前,我在玩完原作的时候,只觉得这是一个美好的,有些浪费设定的盛夏童话。然而,四年之后,在经历了那些晚上睡不着逃避明天,白天愁到在办公室的椅子上无法动弹,焦虑到连关门都要反复检查的日子之后。再次面对这个故事,我却只想叹气。
我想,透过那些日子,我稍微理解了夏生,理解了这个绝望缠身,从研究院里逃回家乡的少年。
但是很不幸,我没有逃跑的时间和空余,海底也没有高性能AI让我去捞。
我活在能造出这种东西的盛世之前。
是的,我可以闭上眼睛,去做梦或者祈祷,逃避现实。但这无济于事。
必须有人来提出算法,训练模型。有人画出设计图,生产部件。有人研究人们的愿望,把这些东西拼起来,塞进橱窗里,送到人的身边。
她是人的造物,是人们怀着亘古以来的祈望,用数百年来自然与社会科学的产物与洞察,从死物中锻造而出的,活的奇迹。
如果想把这样的奇迹,变成理所当然的日常,我,以及和我有着同样愿景的人,就必须行动起来。
如果当前范式无法达成目标,就开发新的范式。无法开发新的范式,就追求当前范式的极致。若是不能亲自下场,就统合整理前人的工作,教育后人,为他们的攀爬提供基石。
我们必须行动。
除此之外,别无他法。
于伊甸中长眠的孩子啊,祝你好梦!
我须诀别梦乡,步入醒时的世界。
深度学习相关领域
某位心比天高,命比纸薄的博士生
约翰板桥
2024年10月6日
附录A:关于题图
本文封图是《亚托莉 - 我挚爱的时光》的女主角,亚托莉。图约稿自半节老师。
嗯,多好的画,多好的孩子啊,不是吗?
附录B:具体技术栈
下面就是我的常用技术栈:
- 数据存储与处理
- 存储:小规模数据我一般选择放Google Drive上,大规模数据可以考虑使用Amazon S3
- 预处理:很多时候python+pandas就够用了。如果需要处理内存放不下的数据,可以考虑使用大数据处理框架,例如dask
- 算力调度
- 租借:免费的colab当然不错,如果需要长时间租用高性能的GPU,我一般会用runpod.io/vast.ai等廉租GPU服务,大公司的专业云服务很贵,但是隐私性和合规方面会好一些
- 调度:如果只有一两台机器,且同事们都在一个办公室,直接docker做环境隔离+ssh就行,规模再大一点就需要slurm,超大规模就要上基于kubernetes的解决方案了,例如kubeflow
- 环境管理
- 最基本的是virtualenv,但是virtualenv无法管理cuda版本,所以我一般用conda来顺带管理其它的原生依赖,但是conda很慢,所以实际上用的是mamba。对于少数非常复杂的,需要用操作系统包管理器安装的东西,docker隔离很有用
- 如果想用conda/mamba管理cuda环境,请见cudatoolkit和cudatoolkit-dev包,这两个包不包含最新的cuda(12+),这方面请见nvidia源的cuda-libraries-dev和cuda-nvcc包。
- 最基本的是virtualenv,但是virtualenv无法管理cuda版本,所以我一般用conda来顺带管理其它的原生依赖,但是conda很慢,所以实际上用的是mamba。对于少数非常复杂的,需要用操作系统包管理器安装的东西,docker隔离很有用
- 实验监控
- 最基础的是tensorboard,需要更多功能/云服务版的话weight and bias(wandb)非常好用,开源/自建可以用mlflow
- 超参数搜索简单的可以直接bash脚本硬刚,专业的有ray的optuna
- 自动化脚本
- bash不可不谓是好用,但是复杂脚本还是用python舒服一些
深度学习方面,除了标配的深度学习框架Pytorch/Jax外,有些提供构建块的库也值得看看。例如图像质量指标(FID/LPIPS等)方面的IQA-Pytorch,三维算法的Pytorch3D,NLP和diffusion方面Huggingface的transformer和diffusers。要找的话建议搜索awesonme-deeplearning/awesome-pytorch这类的github repo。
深度学习还有一些框架性的库,例如Pytorch Lightning。这类库抽象掉了训练代码中那些支持性的代码,但这就要求用户了解这个库所做的抽象,这可能会让代码理解起来更困难些。